Feedback
The CrateDB Guide¶
Guides and tutorials about how to use CrateDB and CrateDB Cloud in practice.
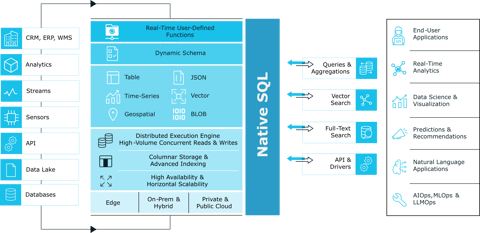
CrateDB is a distributed and scalable SQL database for storing and analyzing massive amounts of data in near real-time, even with complex queries. It is PostgreSQL-compatible, and based on Lucene.
Application Domains¶
Learn how to apply CrateDB’s features to optimally cover use-cases in different application and topic domains.
Integrations¶
Learn how to use CrateDB with 3rd-party software applications, libraries, and frameworks.
Reference Architectures¶
Reference architectures illustrating how CrateDB can be used in a variety of use-cases.
Tip
Please also visit the Overview of CrateDB integration tutorials.
See also
CrateDB and its documentation are open source projects. Contributions to the pages in this section and subsections are much appreciated. If you can spot a flaw, or would like to contribute additional content, you are most welcome.
You will find corresponding links within the topmost right navigation element on each page, linking to the relevant page where this project is hosted on GitHub.