Introduction: Publish-Subscribe Model
Logical replication in CrateDB is based on the publish-subscribe model. In nutshell, the publisher is a database instance that makes data available to other locations through publications. Publications contain tables that are available for replication. Besides data, all operation types such as INSERT, DELETE, UPDATE and schema changes are also replicated.
Let’s take a look at how to make a new publication on a current cluster. To do so, use the following command:
CREATE PUBLICATION name
{ FOR TABLE table_name [, ...] | FOR ALL TABLES }
The newly created publication can contain several tables or all tables on the publishing cluster. If FOR TABLE or FOR ALL TABLES parameters are not specified, the publication will start with zero tables. Leaving parameters empty can be useful if tables need to be added later.
The subscriber is a database instance that receives replicated data from one or more publishers. Also, the subscriber may have several subscriptions and the creation of a new subscription triggers the replication process. The following command creates a new subscription:
CREATE SUBSCRIPTION subscription_name
CONNECTION 'path_to_publisher'
PUBLICATION publication_name [, ...]
[ WITH (parameter_name [= value], [, ...]) ]Now let’s take a look at each parameter.
-
The
subscription_nameuniquely identifies the newly created subscription. -
The parameter to the
CONNECTIONcommand is a string containing the URL of the publisher and the parameters required to establish the connection:crate://host:[port]?parametersThe parameters are passed in the key-value format and separated with
&. For example, the most common parameters are user, password, and sslmode. With these parameters, the connection string looks like:crate://host:[port]?user=my_user&password=1234&sslmode=disable -
The
PUBLICATIONcommand specifies the names of the publications to subscribe to -
WITHclause allows further parameters of the subscription. Currently, only the enabled parameter is supported which specifies whether the subscription should be actively replicating.
Existing publications can be further modified. The following commands illustrate how to add more tables, replace existing tables, or remove tables from the publication:
ALTER PUBLICATION name ADD TABLE table_name [, ...] // add one or more tablesALTER PUBLICATION name SET TABLE table_name [, ...] // replace tables with new listALTER PUBLICATION name DROP TABLE table_name [, ...] // delete one or more tables
If a table gets removed from the publication, the replication of this table stops for all subscribers. Furthermore, if you want to delete an existing subscription you should use the DROP SUBSCRIPTION command:
DROP SUBSCRIPTION [ IF EXISTS ] nameIt is important to note: that altering existing subscriptions is not currently supported. Furthermore, it’s not possible to resume dropped subscription.
Use Cases
There are several use cases that leverage logical replication. In this post, we will focus on two common ones: replication to a central cluster for further data aggregation and reporting and improving data locality by bringing data closer to the user.
Centralized Reporting
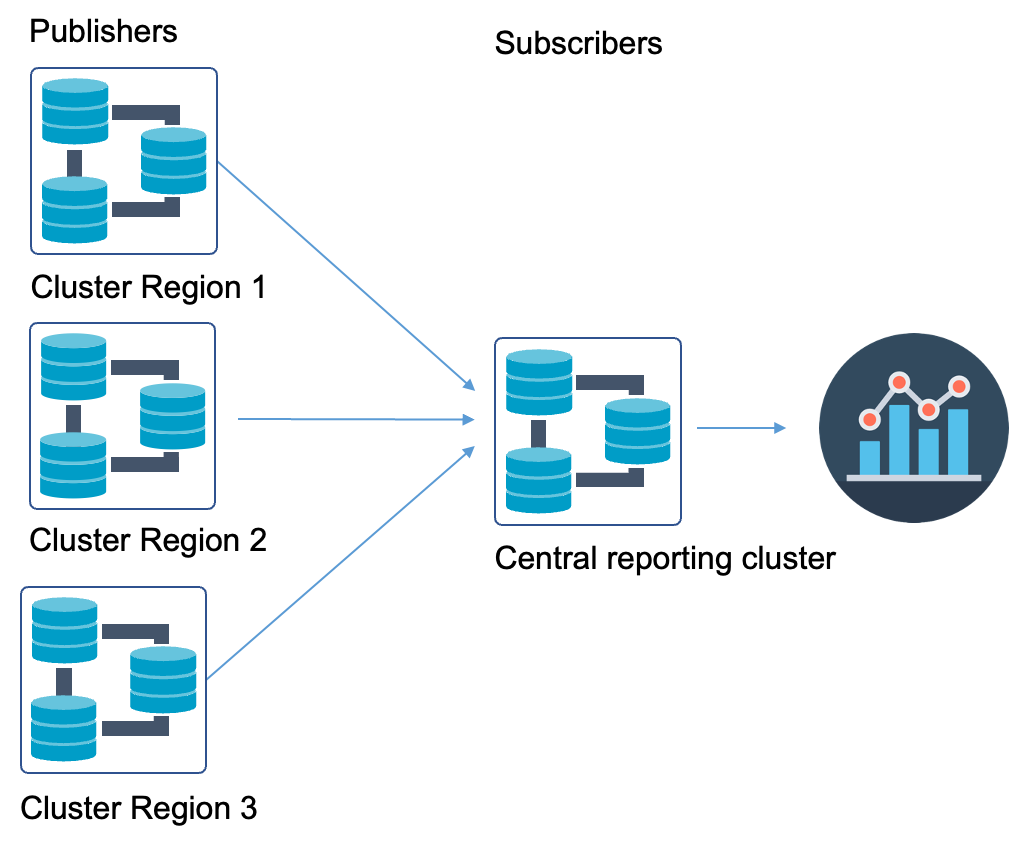
Using a centralized reporting cluster is useful for consolidating data from multiple geographically distant clusters. In this case, after replication, data can be filtered, aggregated, and prepared for further analytics. Additionally, using a central cluster helps when querying across a large network which may incur long delays.
In the following diagram, data from three clusters in different regions is replicated to a central cluster. In this use case, data required for aggregations and analysis can be retrieved closer to where the analysis is taking place which significantly improves reporting efficiency.
Improving Data Locality
Improving data locality can be achieved by replicating data from a distant cluster to many clusters that are geographically closer to the application servers. This improves the latency and response time as it minimizes the distance between required data and applications.
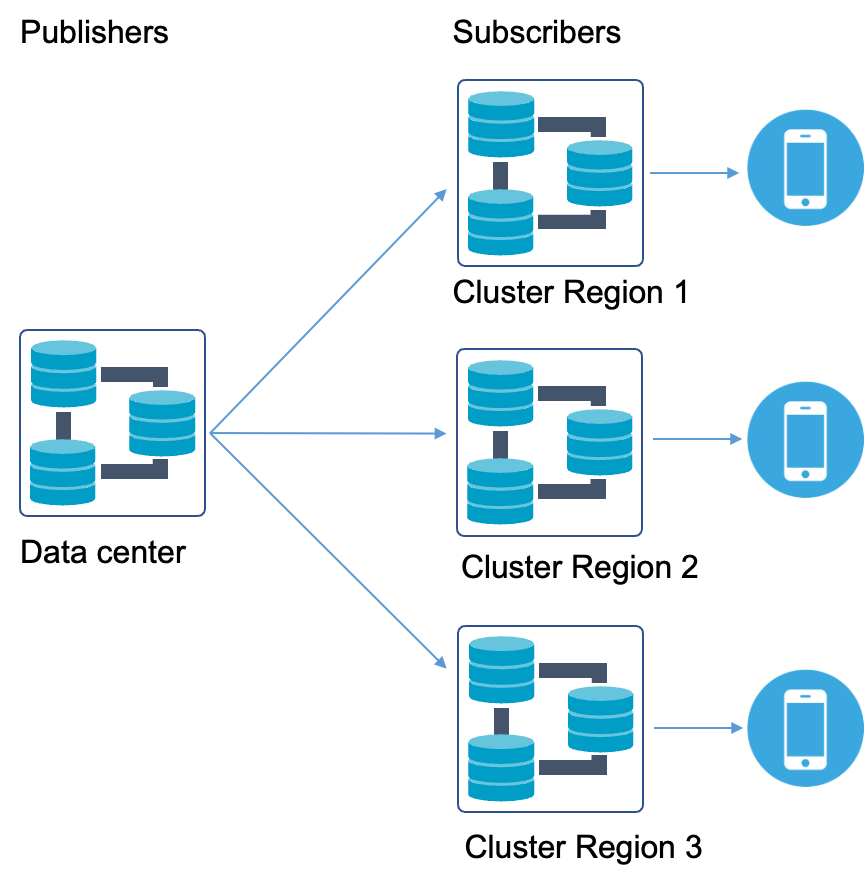
The following diagram illustrates the replication of data from one data center to three clusters in different regions. The additional clusters contain the replication of data required for that particular region. This improves the data locality and reduces the time application needs to access the data.
Besides centralized reporting and improving data locality, logical replication is very useful for the following use cases:
-
Replicating between different versions of CrateDB, and
-
Disaster recovery and high availability in case of cluster failure.
Wrap Up
In this post, we covered the logical replication feature in CrateDB. It follows the publish-subscribe model where the subscriber pulls data from the publications they subscribe to. Using logical replication helps to ensure data recovery in case of cluster failure and allows you to replicate data across geographically distant clusters, in order to bring data closer to the user.
We are working hard on improving CrateDB further and new features will be released soon. To keep track of the newest releases, watch our website for future announcements and posts.