In November, Emily Woods (@sometimes_milo) and I (@autophagian) gave our first ever workshop together. We ran the workshop with PyLadies Berlin.
PyLadies is a mentorship group with a focus on helping more women become active participants and leaders in the Python open-source community. We couldn't have done this without the Berlin chapter of PyLadies, who hosted us, provided food, and organized assistant coaches for the event. Thank you so much!
Our workshop focused on two things: DevOps and Docker.
We've both learned about these two topics working at Crate, and we wanted to package up some of that knowledge and experience and share it with the community.
In this post, I will outline the two introductory talks we gave, explain the structure of the practical component of the workshop, and finish with some takeaways.
If you want to follow along, the slides we used and the accompanying code is available on GitHub.
Talks
On DevOps
Emily kicked off the workshop with a talk about the origin of "DevOps" and its various meanings (and sometimes non-meanings). In her talk, she emphasized that DevOps isn’t a role or a set of tools, but a philosophy—a way of approaching software development in a more process-oriented way.
In a fairly traditional setup, a company might have three separate IT departments: development, testing (QA), and operations.
Work happens like this:
- Developers write code to fix bugs or add features and enhancements to the principal software product.
- Once a piece of development work is finished, it is handed over to the testers who try to verify that it does what it's supposed to do.
- After the work is tested, it's handed over the operations team who then deploy it, run it, and monitor its ongoing status.
If everything goes to plan, this way of doing things is fine.
Unfortunately, as you might know, many things related to software development often do not go to plan. :(
Imagine, for instance, that the operations team dutifully deploys the latest version of the software as requested. However, when it runs, there's a memory leak that nobody spotted during testing because there's a subtle difference between the testing and production environments. That memory leak starved a bunch of other processes, causing a whole collection of services to crash, which leads to unscheduled downtime that ultimately affects paying customers.
It's red alert time.
The only thing the operations team knows is that processes are crashing. They're not familiar with the code, and they have no easy way to diagnose what's causing the runaway memory consumption. So, with no other options, the code is quickly rolled back, systems are brought back online, and an incident post-mortem is initiated.
Management is upset. Tensions are high.
Figuring out what went wrong and which team is responsible gets messy, fast.
The developers are annoyed that the testers didn't do their job correctly. The testers are annoyed they're getting the blame for what boils down to an operations oversight. And the operations team is upset because nobody told them about changes that somebody managed to make to the testing environment.
This way of doing things is often derisively known as throwing code over the wall.

Code is thrown over the wall from the dev environment (on the left) to the staging environment to the production environment.
So what's the alternative?
The DevOps solution to this problem is to give the developers the responsibility for the whole software lifecycle. So, developers are no longer just writing the code. They're testing it too, and then deploying it.
Through this process, developers get a better understanding of how their code ought to be deployed and how it runs. And when problems arise, they are ideally situated to react because they have an understanding of the entire system from start to finish.
Issues can be diagnosed quicker, fixed quicker, and communicated faster. And, thankfully, there's no more blame game.
Emily went on to emphasize that anybody can be a DevOps engineer, as long as they're prepared to adapt the way they work and learn how to test, deploy, and run the same software they are writing.
On Docker
After Emily’s talk, I gave an introduction to Docker.
I made a case for Docker (and containerization more generally) using an example of the problem of bundling application dependencies.
You see, deploying multiple independent applications onto the same machine can get quite messy. For example, different applications might want different versions of the same dependency software. This is known as a dependency conflict, and it's a challenging problem to solve.
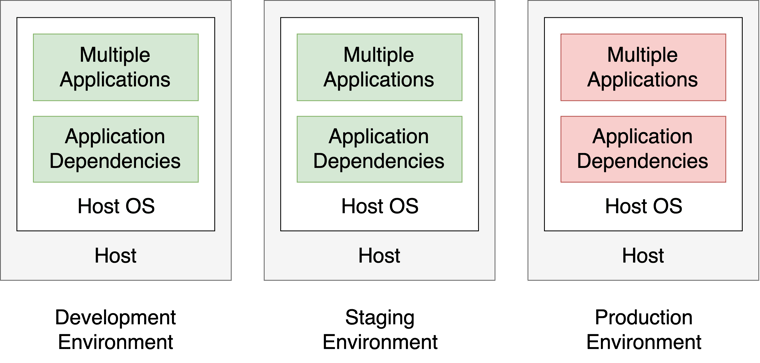 A single software stack is used to run everything. There are no errors in the development environment or the staging environment. But when the changes land in production, there's an unexpected dependency conflict. Eep!
A single software stack is used to run everything. There are no errors in the development environment or the staging environment. But when the changes land in production, there's an unexpected dependency conflict. Eep!
One way to avoid this problem entirely is to use virtual machines (VMs). A VM emulates a physical machine and is capable of running an operating system with its own libraries.
You can deploy each application along with its dependencies into its own VM. Because each VM is isolated from the rest, there is no longer any possibility of a dependency conflict.
We can then bundle our applications separately into virtual machines, so that their dependencies (and the applications themselves) are sandboxed, thereby solving our dependency problem.
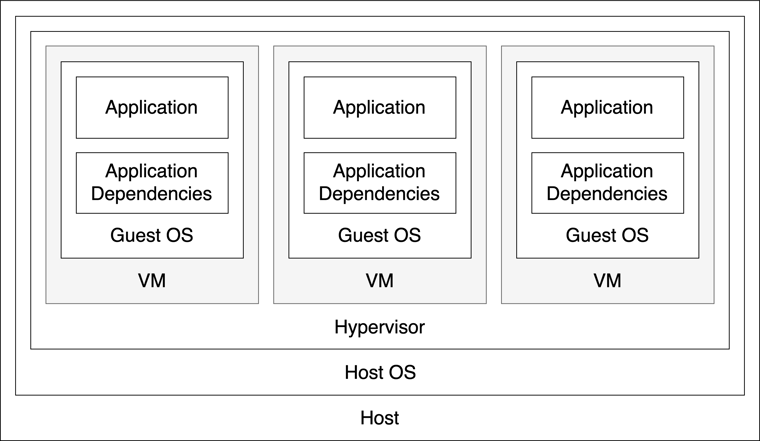 A single server can host multiple virtual machines, each with its own software stack. In this example, the three virtual machines might run three separate applications: a web server, a database, and a batch processing daemon.
A single server can host multiple virtual machines, each with its own software stack. In this example, the three virtual machines might run three separate applications: a web server, a database, and a batch processing daemon.
However, there's still a problem with this picture.
Look how many things we have inside other things. Look how many times we have to virtualize some hardware running its own operating system.
That's a lot of complexity. And a lot of wasted resources! Each guest OS needs its own disk space, its own CPU time, its own RAM.
Fortunately, Docker solves this problem by sharing the host operating system with each container, thus eliminating the need for hardware virtualization.
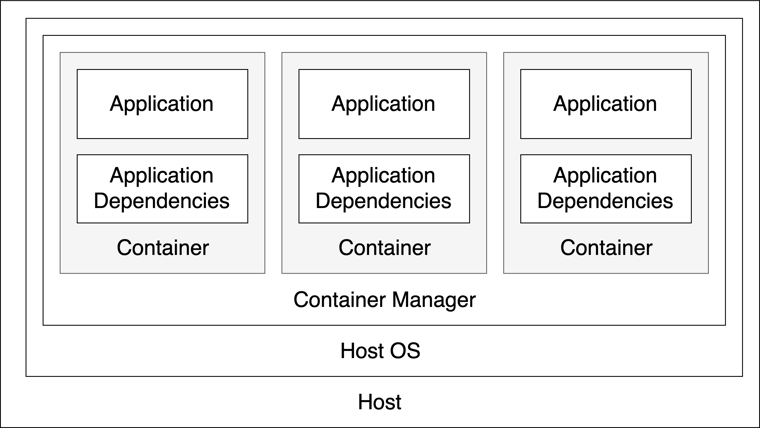 Each container runs an isolated process (the application). The host operating system kernel is shared with each container. Admittedly, we still have quite a few things inside other things.
Each container runs an isolated process (the application). The host operating system kernel is shared with each container. Admittedly, we still have quite a few things inside other things.
Containers are implemented using Linux namespaces and cgroups, meaning they're super lightweight and do not need any dedicated resources.
Docker also makes use of AuFS (a multi-layered union mount file system) meaning that duplicate files (e.g., common libraries) are only written once to disk.
The end result is a system that uses a lot fewer resources and can spin up new containers in seconds instead of minutes.
Check out this StackOverflow question for a more in-depth explanation of the differences between using Docker and VMs.
Practical
After mine and Emily's talks, we began the practical half of the workshop by showing participants how to construct their own Docker image.
A Docker image is a bit like a disk image: it contains information about the file system you want to run as a container. Every time you run a Docker image, you get a container that is exactly the same as every other container run with that image.
You can create a Docker image with something known as a Dockerfile.
A Dockerfile is a text file with a list of instructions that tell the Docker engine how to construct the Docker image.
Here's the Dockerfile we used:
Let's break that down:
- We use the FROM directive to specify the official Python 3.7 image as our base image.
- Next, we ADD our project files and RUN pip to install the dependencies.
- Then, EXPOSE tells Docker which port the application uses, and LABEL is used to set some arbitrary metadata.
- Finally, we use ENTRYPOINT directive to tell Docker to run
python mypython.pywhen starting the container. When this process terminates, the container stops, and vice versa.
The mypython.py script is a small Flask web application we built that displays “Hello, World!” when you first navigate to the index page:
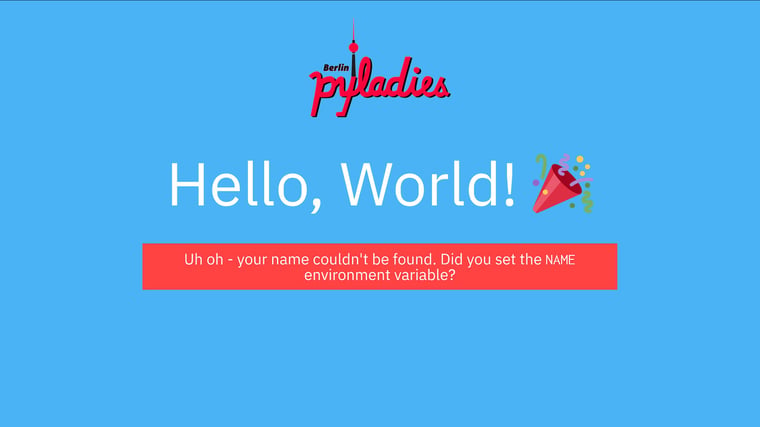
But there's an error...
As you can see from the error message above, the web app is looking for an environment variable called NAME. When this environment variable is present and set to your own name, the error message goes away, and the page text changes to greet you by name. :)
All in all, the participants had two hours to complete the following challenge:
- Run the flask application locally using virtualenv.
- Write a Dockerfile that will install the application along with its dependencies and run the Flask server.
- Map the Flask server port to a port on the host machine and get the Docker container running.
- Figure out how to set the
NAMEenvironment variable so that the application greets the participant by name. - Bonus: Optimise the container by choosing a different base image.
- Bonus: Use Docker Compose to run the Docker image.
The last two items were a bonus for anyone who managed to build and deploy a working application before the end of the workshop.
The Results
Overall, it was a great workshop and a great experience!
We had some issues getting Docker working on some people's Windows machines, but nothing insurmountable. Once everyone was set up, people either worked alone or paired up. By the end of the workshop, people were smiling, making triumphant exclamations, and posting screenshots of their work to Twitter!
Jetzt weiß ich auch endlich was diese ganzen mysteriösen #docker Befehle und Zeilen im Image und Compose File bedeuten, die ich bisher nur Copy-pasted habe 😬 thanks @PyLadiesBer @sometimes_milo & Mika for the great DevOps/Docker Intro! pic.twitter.com/9Vq3r5IJaH
— Alexandra Kapp (@lxndrkp) November 19, 2019
Seeing people overcome that initial frustration to achieve success was super, super rewarding.
We were so nervous about giving the workshop, but everything went really smoothly, and it was definitely worth it.
Lessons Learned
We learned a bunch of things doing this workshop. First and foremost, we learned the value of simplicity.
Our initial workshop plan was to have a partially-completed Flask application that people needed to finish. The app would then register itself with a hosted service and receive push-metrics from an IoT enabled Raspberry Pi with a temperature sensor, humidity sensor, and a luminosity sensor. Registered clients would then show up on a dashboard at the front of the workshop.
In retrospect, this is comically ambitious for a two-hour workshop! :P
Thankfully, we realized this a week before the workshop.
As part of our preparation work, we were attempting to get a Raspberry Pi working with the sensors we had. We hooked the sensors up the Raspberry Pi’s input pins, booted the Raspberry Pi, and, well, nothing.
It wouldn’t boot from the SD card we were using, so we tried a different one.
Again, it wouldn’t boot.
The specifics of what went wrong are unimportant. But if it could go wrong so easily, we came to the conclusion that adding hardware hacking to the mix was a recipe for frustration. Not to mention the issues we'd face if the local network went down on the day of the event.
So, we set to work refactoring our idea.
We had two main objectives:
- Make failure less likely
- Narrow the focus
In the end, this worked really well, and it made the workshop easier to organize and more straightforward to follow.
We love hardware hacking, though, so it was a bit of a shame to lose that aspect. However, we are thinking about doing another workshop. And, if we do one, we might focus on the Raspberry Pi and maybe do an all-day workshop. We'll see.
Wrap up
We're very grateful PyLadies Berlin gave us the opportunity to do this workshop, and we'd love to collaborate with them again. We would also like to thank all of the people who came for making the experience as joyful and as fun as it was.
Several people at the workshop asked me superb questions about the fundamentals of Docker and containers that I honestly had no idea how to answer.
I hadn't even though to question those things and it made me realize how many assumptions I had made and how those assumptions were some of my blindspots.
After the workshop, I sat down at my laptop to try to answer the questions that had come up. And, in the process, I learned a bunch of new stuff.
It's fascinating to me how, in making an effort to teach, I ended up significantly broadening my own understanding!