
CC-BY-SA 2.0, Ozzy Delaney
Writing data to a database is a task that most developers want to complete as quickly as possible. This is especially true when an application or device is recording time series data at regular intervals. A database needs to keep up or data might become inconsistent.
Replication in CrateDB
At the same time, data integrity and availability are equally important. CrateDB maintains replicas of data to assist with data consistency. When creating a table, you configure this with:
CREATE TABLE ... WITH (number_of_replicas = 2);When inserting data with replicas enabled, CrateDB inserts the data on the primary node first and then schedules the insert to all configured replicas in parallel. The request returns when all replicas are written. This means that inserts with replication will always take longer than inserting into an un-replicated table.
By introducing a smarter handling of bulk operations we could reduce the amount of internal communication dramatically: CrateDB previously forwarded each insert to replicas separately, but now utilizes bulk requests to replicate batches of data. With this we were able to greatly increase CrateDB's performance for replicated tables.
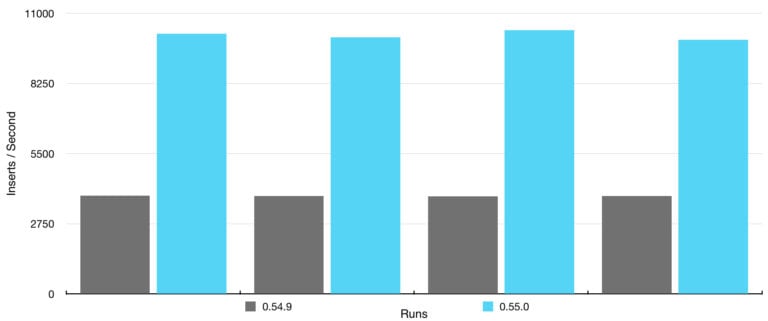
We set up a two node cluster that replicated each data shard once. Compared to an earlier version, CrateDB 0.55.0 completed the ten million bulk inserts operation twice as fast for almost every run! The improvements are in our testing release, so we invite you to play with it and tell us what you think.
Benchmark Setup
The setup was reasonably simple. Two nodes holding a table (with one string column) distributed within two shards, with one replica. Then we issued bulk requests to insert batches of 1000 rows (each with a random 512-byte string) multiple times, and took the duration returned by the server. The goal was to focus on the algorithmic change (contrary to saturating I/O), therefore we could run the benchmark on a single machine and achieve that speedup.
Don't take our word for it. In our GitHub repository you will find all the necessary scripts to reproduce our experiment and try it for yourself.