The CrateDB query execution pipeline used to be push based. But over time, we ran into problems with this approach. It made the code complex and hard to work with, and it was limiting the sorts of join algorithms we could implement.
To fix those problems, and to open up the possibility of implementing more efficient join algorithms, the past couple of weeks my team and I have spent some time overhauling the execution pipeline.
In this post, I’ll briefly introduce you to the problem we were trying to solve, and how we went about solving it.
Introduction
What do I mean when I say that the query execution pipeline was push based?
Well, it means that we had some kind of data source—either on disk, in memory, or held remotely—and then a component (that we call a CrateCollector, or just a collector for short) would read that source and feed the data, row by row, into a different component.
We called this receiving component the RowReceiver. RowReceiver components can then be chained, to construct projections. Projections are then used for all sorts of things. For example: evaluating a scalar function, filtering rows, limiting rows, grouping with aggregation, and so on.
On a high level, RowReceiver components are handled like this:
for (Row row : inMemorySource) {
boolean continueFeeding = rowReceiver.setNextRow(row);
if (continueFeeding == false) {
break;
}
}
Here, we can see that RowReceiver will be fed rows from the memory source until we run out of rows or until the setNextRow() returns false.
If we’re implementing a filtering component, the implementation of setNextRow() might look a little something like this:
public boolean setNextRow(Row row) {
if (matches(row)) {
return rowReceiver.setNextRow(row);
}
return true;
}
Here, if the matches() function returns true, we call setNextRow() on the next RowReceiver in the chain, effectively allowing the row to be set. Otherwise, we skip the row.
Thing Start To Get Tricky
This would all be fine if the data flow was as simple as the Collector reading some data and feeding it through a pipe of RowReceiver components. But sometimes, RowReceiver components needs to write data to other nodes (for example to index new documents or forward data).
This is a problem because while a RowReceiver component is waiting to complete these write operations, data is being continuously pushed into it. And there is a real risk that its buffer would fill up.
To solve this, we had to figure out a way to apply back pressure to (i.e. intentionally slow down) the chain of RowReceiver components.
The way we solved this initially was to modify the RowReceiver interface.
Instead of returning true or false, we changed setNextRow() so that it returned a Result enum. This enum could be one of three values: CONTINUE, PAUSE or STOP.
The PAUSE value would indicate that the upstream should stop calling setNextRow() until it was told to resume.
In order to provide the downstream a way to resume the upstream we added a pauseProcessed() method with a ResumeHandle. This ResumeHandle in turn has a single function, named resume().
Here’s a simplified diagram of how this works:
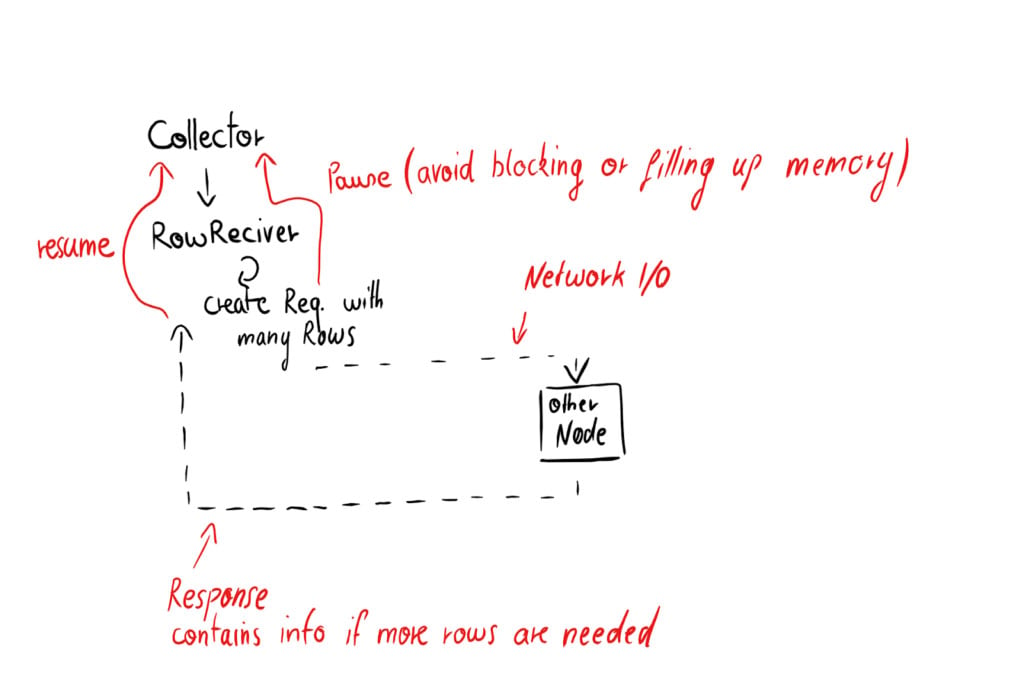
The RowReceiver component sends rows to another node, and indicates to the upstream that it should pause the incoming data flow. Once the RowReceiver component gets the response from the other node and concludes that it wants to receive more rows, it indicates to the upstream that it can resume.
Here’s our updated example code:
# upstream - the component feeding data
Iterator it = inMemorySource.iterator();
while (it.hasNext()) {
Row row = it.next();
Result result = rowReceiver.setNextRow(row);
switch (result) {
case CONTINUE:
continue;
case PAUSE:
// save iterator state; resumeHandle can be used to
// re-active the upstream and continue row-feeding.
rowReceiver.pauseProcessed(resumeHandle);
return; // exits stack on thread
case STOP:
// finish tells the RowReceiver that the upstream sent all
// available rows.
rowReceiver.finish();
return;
}
}
Things Start To Get Even More Tricky
This architecture we outlined in the previous section served us well, until we started to implement joins.
We started our work on joins by implementing the nested loop algorithm. Although it is suboptimal in many cases, it is the simplest algorithm, and can be used for all join variants (and with extensions, even outer joins).
A nested loop join looks like this:
for (Row leftRow : leftSource) {
for (Row rightRow : rightSource) {
Row combinedRow combineRow(leftRow, rightRow);
// if inner join, see if combinedRow matches join-condition
// do something with combinedRow
// ...
}
}
But how does this work with our push based data flow?
Well, for starters, one aspect of the nested loop is that the right side is enumerated for every row on the left side. So, to enable that, we need a way to tell the upstream RowReceiver to send all the data again.
To accomplish this, we added a RepeatHandle with a repeat() method.
And then we implemented a NestedLoopOperation which had two RowReceiver components, one for the left side, one for the right side.
Despite the name, both of these RowReceiver components have to run in parallel, receiving rows concurrently, and are then synchronised. This counter-intuitive constraint is because CrateDB query execution is push based and distributed across multiple nodes. So the component implementing the nested loop algorithm isn’t necessarily on the same node as the row collectors.
And this is where things started to get complicated, because of the many possible states that need to be handled.
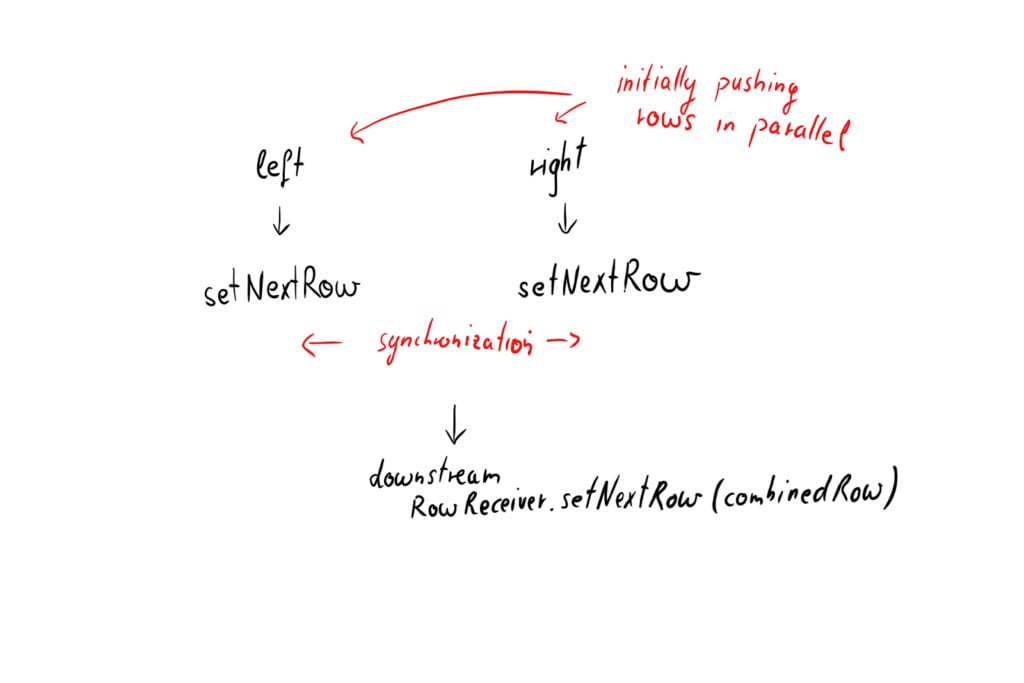
Here’s what the code looks like:
// left
Result setNextRow(Row row) {
// Did the right side start yet?
// Did the right side finish without rows?
leftRow = row;
someHowSwitchToRight();
return result; // result depends on whatever happened in the right side
}
void finish(RepeatHandle repeatHandle) {
// Is the right side finished?
// Did the right side receive any rows?
}
// right
Result setNextRow(Row row) {
// Did the left side start yet?
// Did the left side finish without rows?
// Do I have a left row ?
// ...
}
void finish(RepeatHandle repeatHandle) {
// Is the left side finished?
// Did the left side receive any rows?
// Is it necessary to resume the left side?
}
We eventually managed to tackle this complexity, but it only became worse once we added support for left, right, and full outer joins.
The increase in complexity was due to the fact that extra can rows are created. For example, in the left join case, after each right iteration, a row where the right side is null is created if there was no match.
The code from before evolved into something like this (simplified):
// right side
void finish(RepeatHandle repeatHandle) {
// Is the left side finished?
// Did the left side receive any rows?
// where there any matches?
// if not:
// result = downstream.setNextRow(rowWithRightSideNulled);
// handle CONTINUE, PAUSE, STOP
// Is it necessary to resume the left side?
}
Looking for a Solution
With all the complexity our approach introduced, we ran into quite a few bugs.
We managed to iron out the bugs eventually, but we didn’t feel comfortable adding any additional join algorithms. Which was a problem, because, as I mentioned previously, the nested loop algorithm is one of the least efficient.
So, we started to look for a way we could reduce complexity.
Two options came to mind:
- Save all right rows into an in-memory structure. This would allow us to iterate over all right rows for every left row, without having to re-read the right rows from their source.
- Switch to a pull-based execution flow.
Unfortunately, while using an in-memory structure would be simplest to implement, it would also mean that joins could only be done over row sets that fit into memory.
Given that the nested loop algorithm should eventually function as the fallback algorithm that we use when more efficient algorithms (currently not implemented) are not possible, and the massive datasets that CrateDB is designed to work with, we had to reject this approach.
This left us with the second option: pull-based execution architecture.
From Push to Pull
Once we’d settled on moving to a pull-based execution architecture, we started evaluating different approaches.
We had a few simple requirements:
- Low per-row overhead
- Support for non-blocking (network) I/O operations
- Support for using shared objects to avoid heap allocations
- Should allow us to utilize primitive types in the future and enable us to have CPU cache friendly data structures underneath.
The first two requirements dictated batch-style row processing. It also ruled out re-using any existing interfaces like Stream or Iterable, as these don't support non-blocking operations.
What we eventually ended up with is a bit of a mix between Iterable, Iterator, and what could be described as cursor.
We call it BatchIterator, and it looks like this:
interface BatchIterator {
// contains accessors for the data; depending on the iterator's position
Columns rowData();
// puts the iterator into start position
// (required for repeated consumption in the nested-loop)
void moveToStart();
// move to the next position;
// if false loadNextBatch can be used to load more data
// or if allLoaded is true the iterator is exhausted
boolean moveNext();
// load more data asynchronous
CompletionStage<?> loadNextBatch();
// indicates if all data has already been loaded
boolean allLoaded();
// releases any resources used by the iterator
void close();
}
The way this is used is still similar to before. We have a source, and then we have projections which transform this source. But instead of the component doing the projection being a RowReceiver, these are now a series of nested BatchIterator components.
For example:
BatchIterator iterator = limit(grouping(filter(source)))In this example, source, filter, grouping, and limit are all BatchIterator components.
A BatchConsumer component will then receive this projected BatchIterator and consume it’s data. Either to transmit the data to another node in the cluster, or to a client, to provide the requested result.
Columns rowData = batchIterator.rowData();
while (batchIterator.moveNext()) {
// do something with rowData
}
if (batchIterator.allLoaded()) {
// we're done
batchIterator.close();
} else {
batchIterator.loadNextBatch()
.whenComplete((r, f) -> // continue consumption );
}
Wrap Up
We’ve migrated all components which involved the RowReceiver to the new BatchIterator interface and removed the RowReceiver interface.
Overall, the complexity of many CrateDB components decreased, so the work has been a success. And now we have this sorted, we’ve opened up the possibility of implementing more efficient join algorithms, like sort-merge join or hash join.