We are happy to announce our official integration with Cube. Now you can enhance your modern data stack with Cube and CrateDB as a starting point for building data-intensive applications.
Firstly, thank you for Cube's excellent support in writing this article!
Continue to read to learn how to configure your modern data stack to build data-intensive apps.
Cube: API-First Business Intelligence
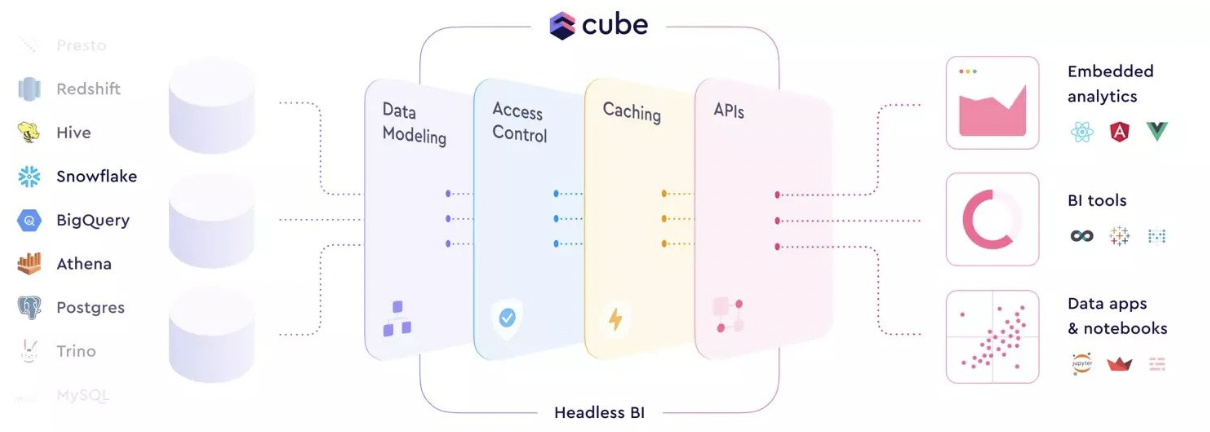
Cube’s headless business intelligence platform makes lakehouse data consistent, performant, and accessible to every downstream application. Cube connects to dozens of warehouses, databases, or query engines, and allows you to quickly build data applications or analyze your data in BI tools.
Cube’s advanced caching and pre-aggregation layer can condense frequently-used queries to optimize response times. While the data modeling provides a central location for your metrics definitions.
Cube provides this data to applications with GraphQL, REST, and SQL APIs so that every tool—and every data consumer—can work with the same data.
CrateDB: Distributed database for real-time analytics
CrateDB is an open-source distributed database management system that makes it simple to store and analyze massive amounts of data in real-time. It is designed to handle various data types, including time-series, full-text search, geospatial, and structured and semi-structured data. In addition, the CrateDB engine is optimized for fast queries and aggregations thanks to in-memory columnar indexes and data compression.
Furthermore, CrateDB offers NoSQL flexibility with an SQL interface. The SQL compatibility makes the integration of CrateDB with other data engineering tools easy and efficient.
In this article, we will demonstrate how to set up a CrateDB cluster and how to use it as a data source in Cube Cloud for further data analysis.
Deploy a cluster on CrateDB Cloud
To deploy a new cluster on CrateDB Cloud, please sign up for a CrateDB Cloud account. When creating a new organization, you are entitled to a $200 free credit to spend on cluster deployment, scaling, and other operations as you see fit.
After the signup process is completed, you will arrive at the CrateDB Cloud Console.
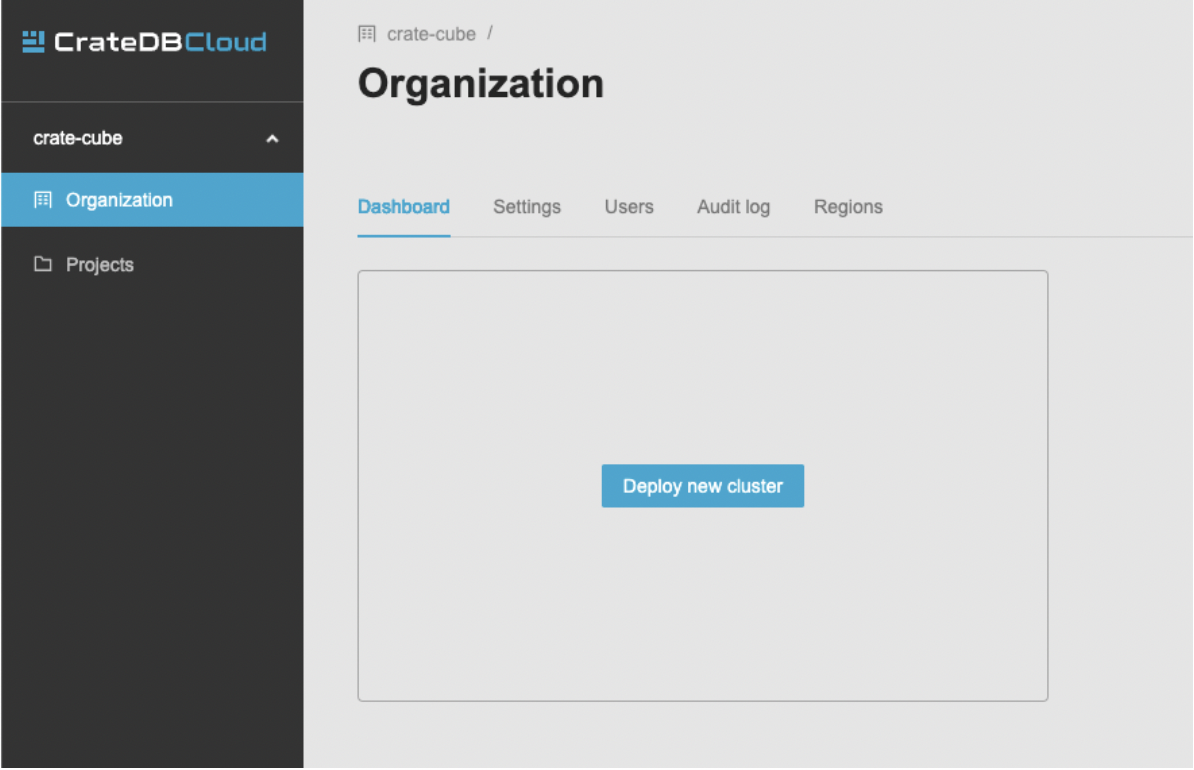
At this point click on the Deploy new cluster button. This will open the cluster deployment screen that consists of three steps: region selection, cluster configuration, and account settings.
As a first step, we will select a region where the cluster will be deployed.

As a second step, we will choose a configuration plan. For each plan, you can see the CPU, RAM, and (minimum) storage values per node.
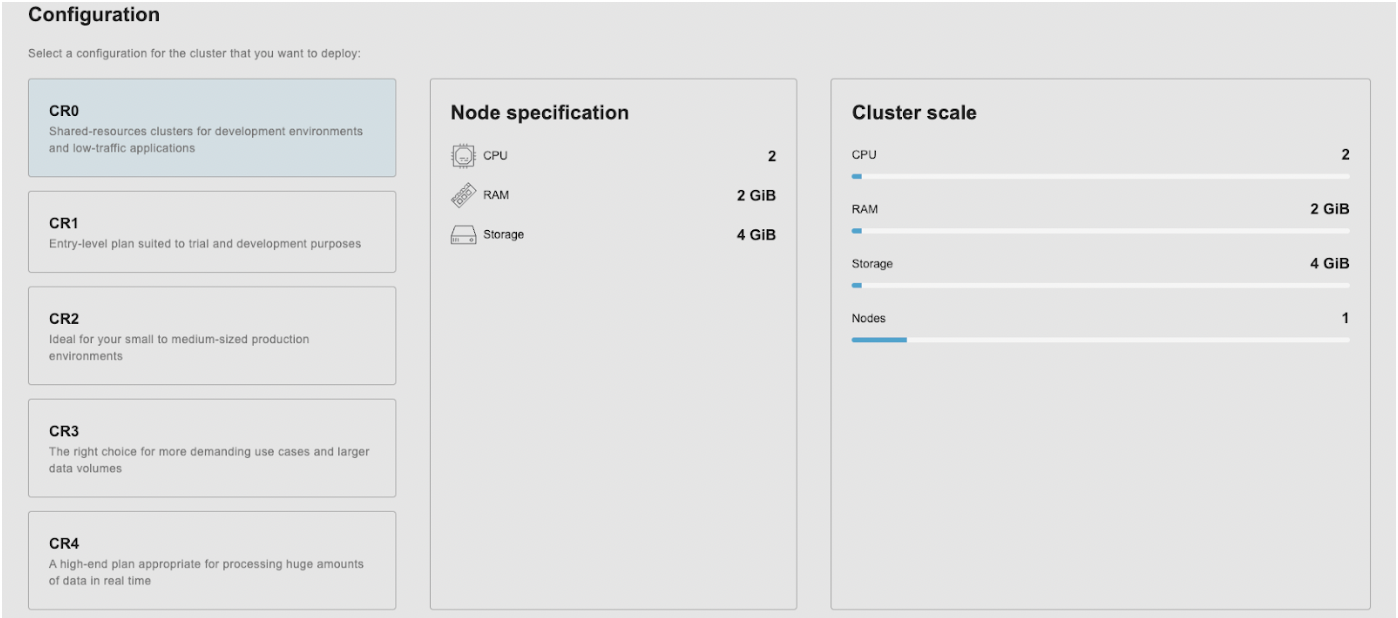
In our case, we will choose the CR0 plan which refers to a shared resource cluster. This type of cluster shares compute and storage resources with other clusters in this category and that allows better utilization of resources.
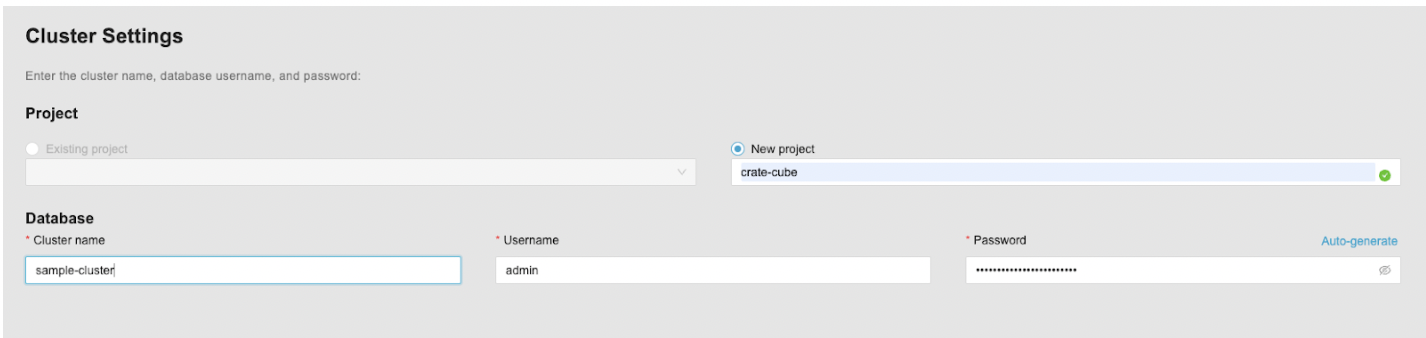
Finally, at the bottom of the screen, you can configure your account settings. In our example we choose the following credentials:
- Project name: crate-cube
- Cluster name: sample-cluster
- Username: admin
- Password: auto-generated
The next step requires the setup of your billing information. You can use existing AWS or Azure subscriptions or credit card information. Once this is completed, you can see the overview of your cluster with instructions on how to connect to the cluster, how to import sample data, and usage metrics.
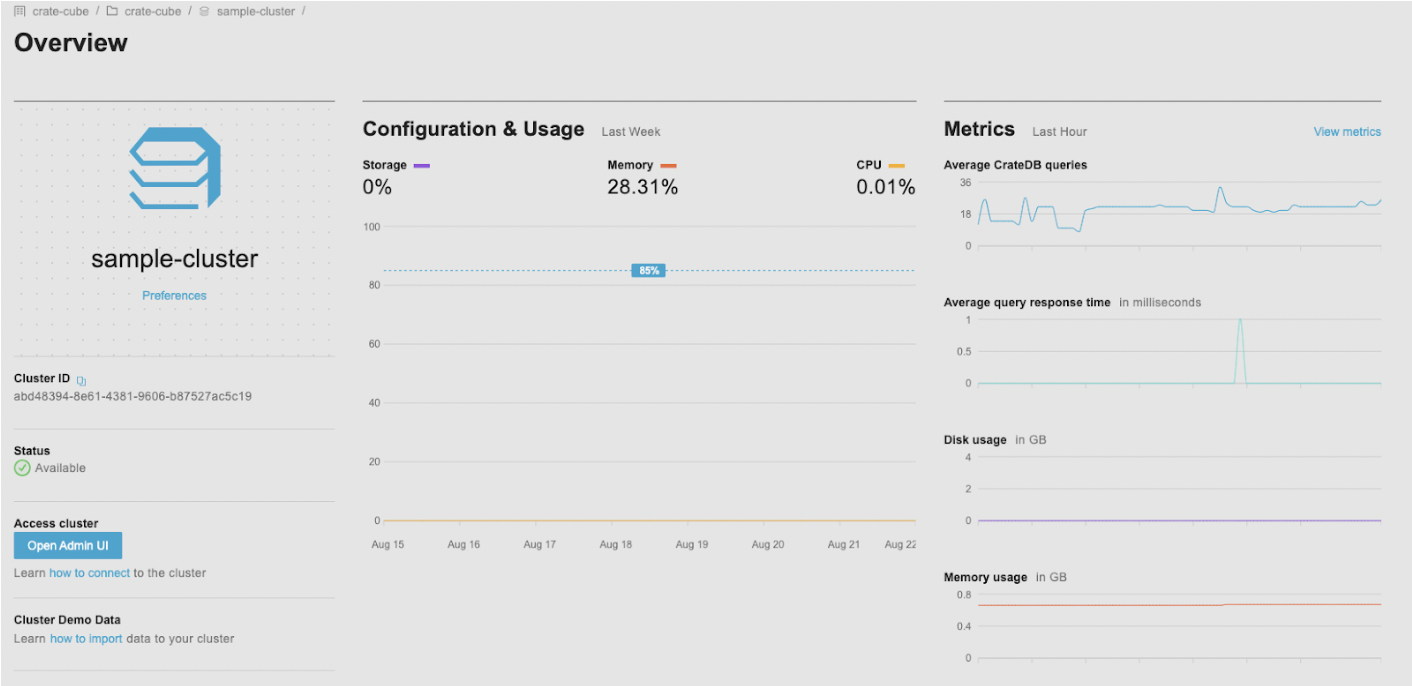
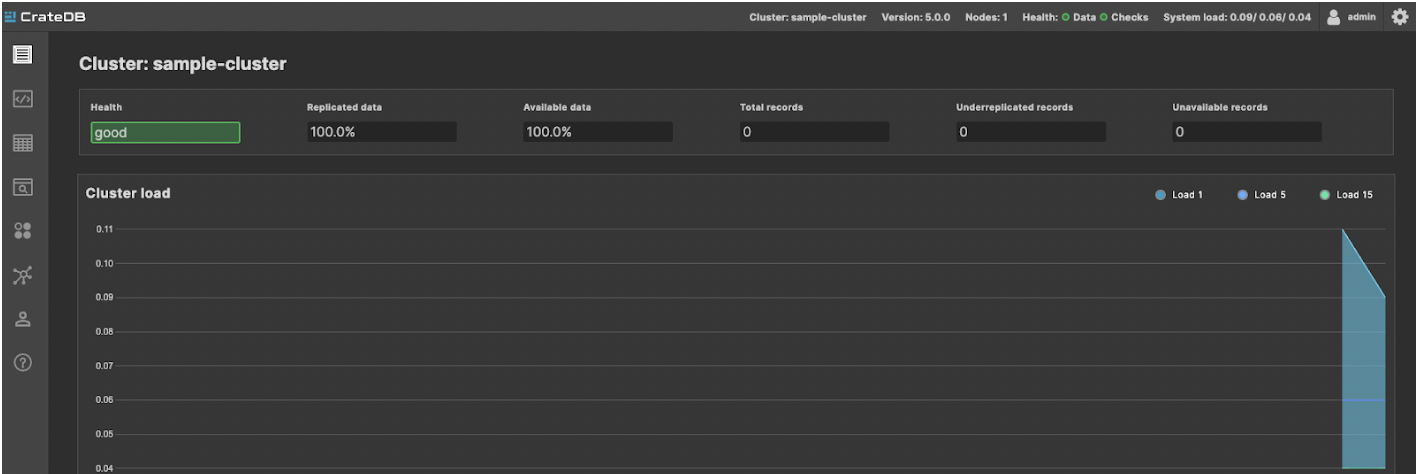
To start creating tables and running queries, click on Open Admin UI. This opens a web administration user interface (or Admin UI) for your running cluster.
Now, let’s import some data. To do so, go back to the cluster overview page and click on Learn how to import data link. This will open a list of statements you need to execute to load NYC taxi data:
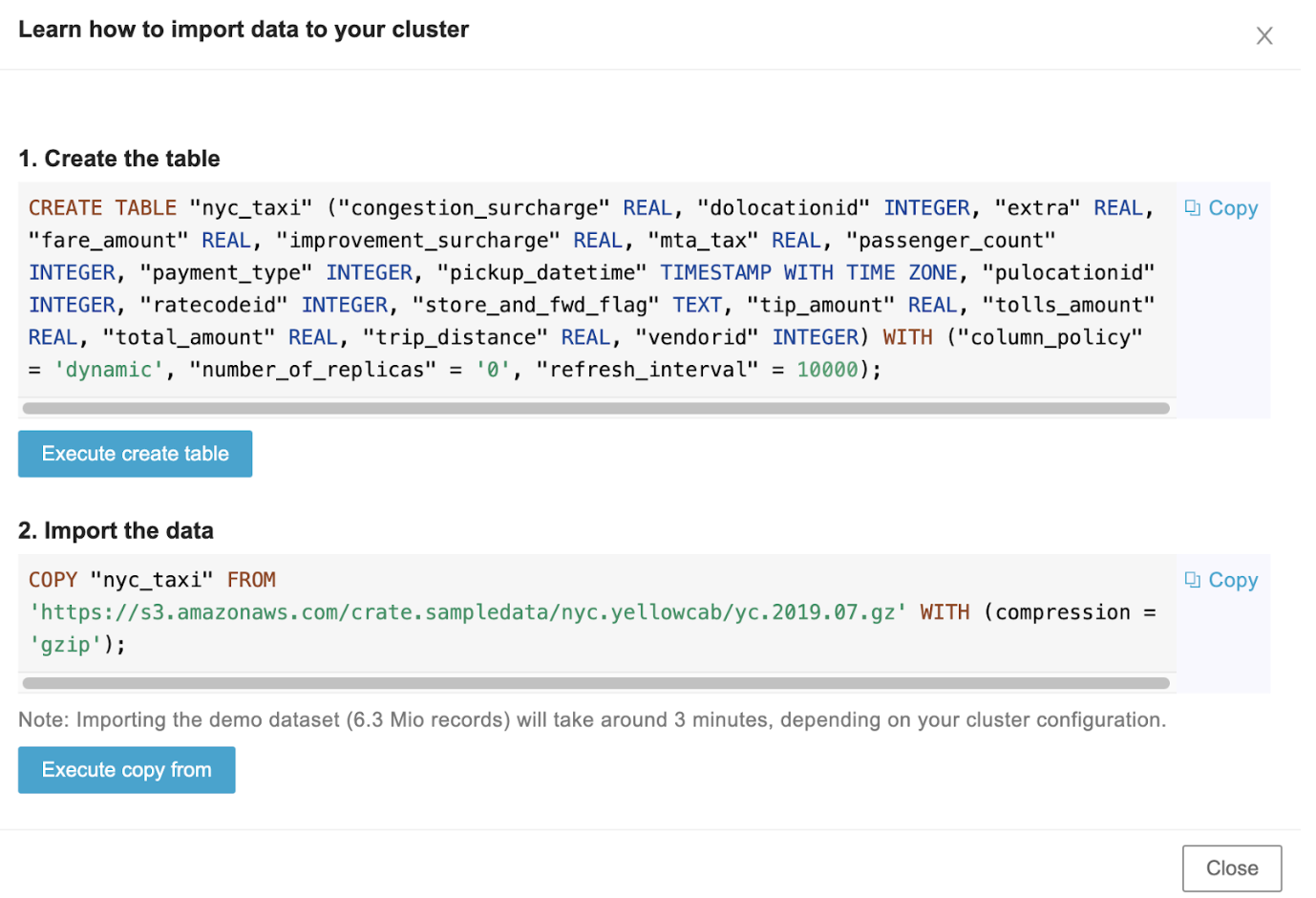 Great! Now that you have the first table in your CrateDB cluster, let’s see how to add this dataset to your Cube Cloud instance.
Great! Now that you have the first table in your CrateDB cluster, let’s see how to add this dataset to your Cube Cloud instance.
Connect CrateDB to Cube
To start with Cube, create a new Cube instance in Cube Cloud. You can sign up for a Cube Cloud account with a free trier.
Once you create a new Cube instance, you will need to create the new deployment. For our cube-crate deployment we choose the cloud provider and the region:

On the next page, we click on the Create tab to set up our CrateDB connection:

To connect CrateDB with Cube we need to specify the database connection of our CrateDB cluster:
- Hostname: sample-cluster.aks1.westeurope.azure.cratedb.net
- Port: 5432 (default)
- Database: crate
- Username: admin
- Password: the password you created during cluster creation
- SSL checkbox: CrateDB Cloud does not allow non-encrypted connections
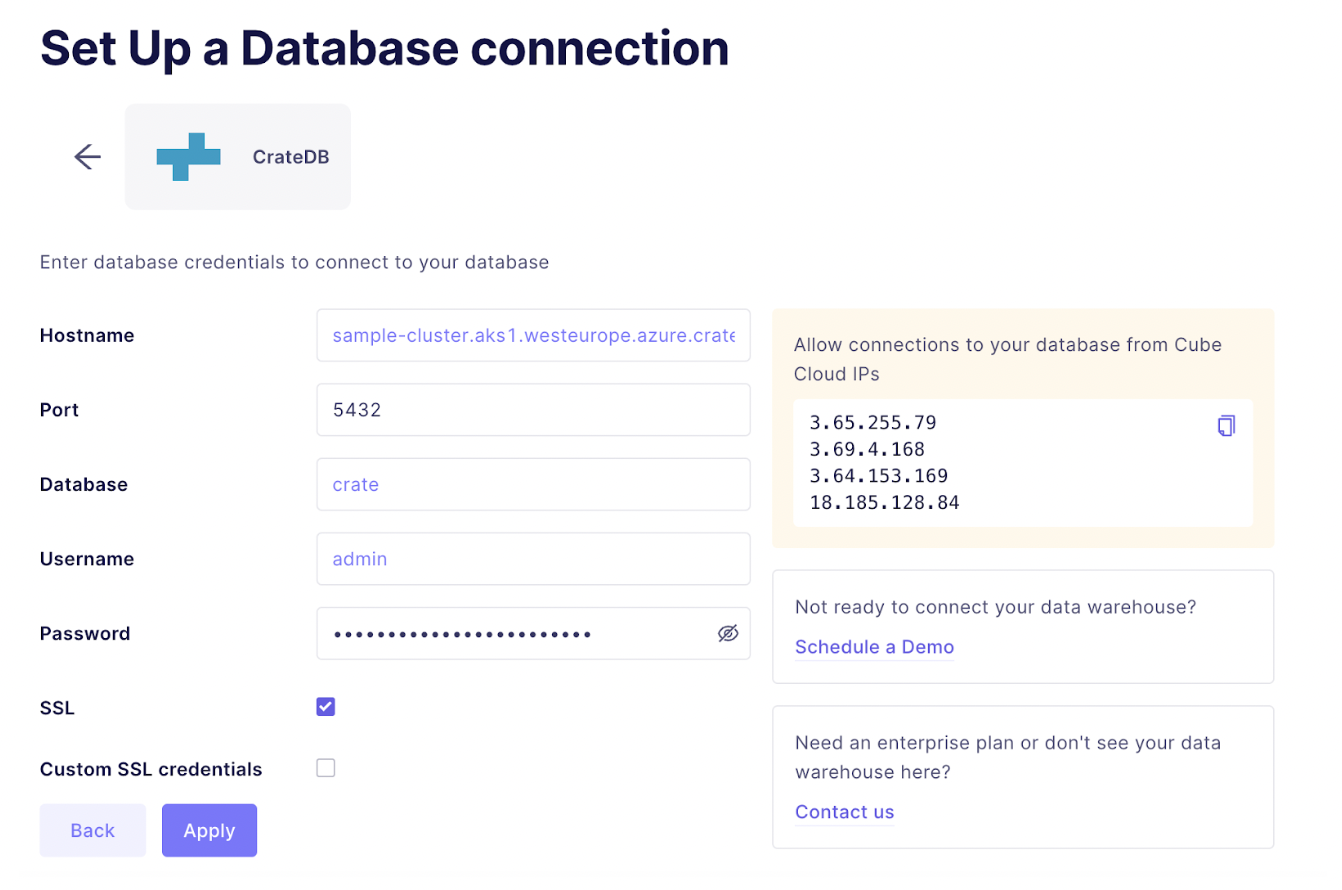
Click on Apply and in the next view select all tables for which you want Cube to generate the initial schema. For instance, we can generate the schema for our nyc_taxi table.
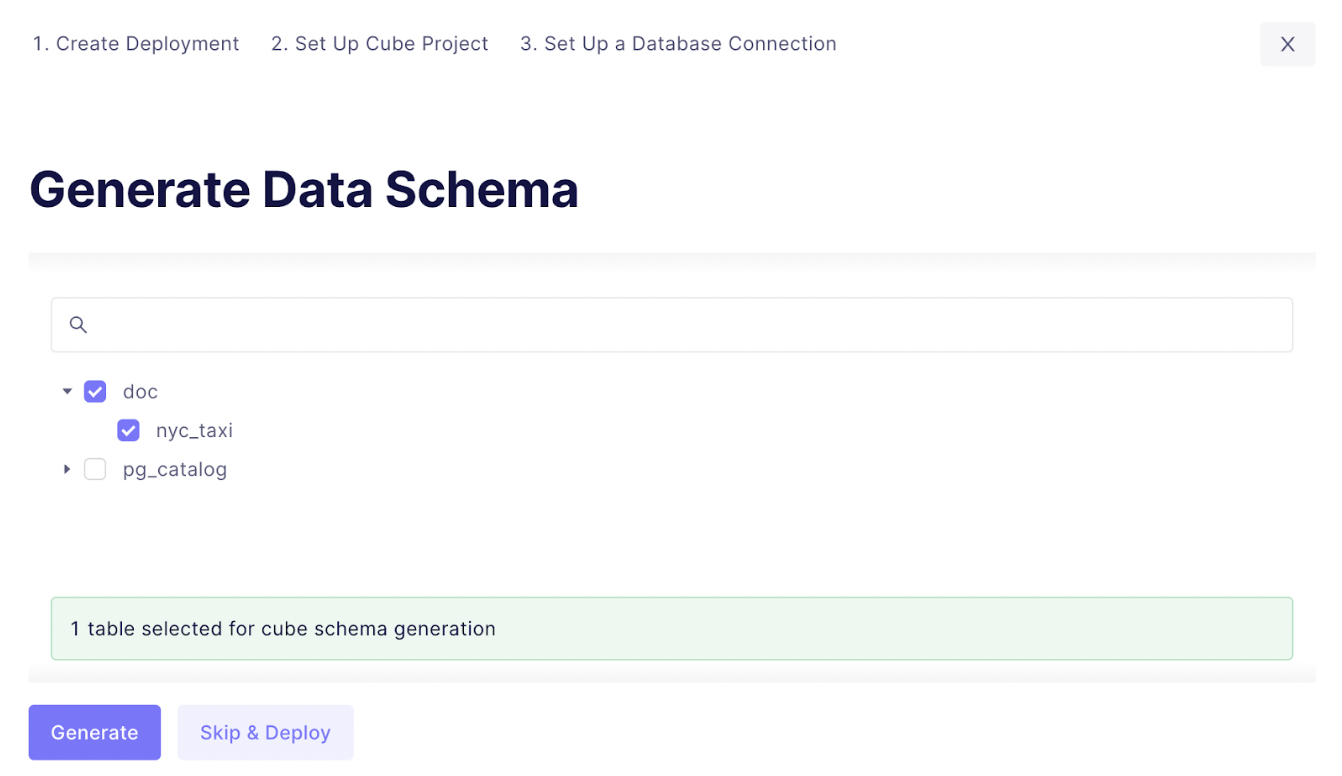
Click on Generate button, wait for a couple of seconds and you will see the newly deployed instance that is connected to our CrateDB database.
From this point, you can start exploring generated schema and defining new data models for your applications!
Cube as a headless BI layer
Let's have a look at the autogenerated schema. Switch to the Schema tab and click the NycTaxi.js file.
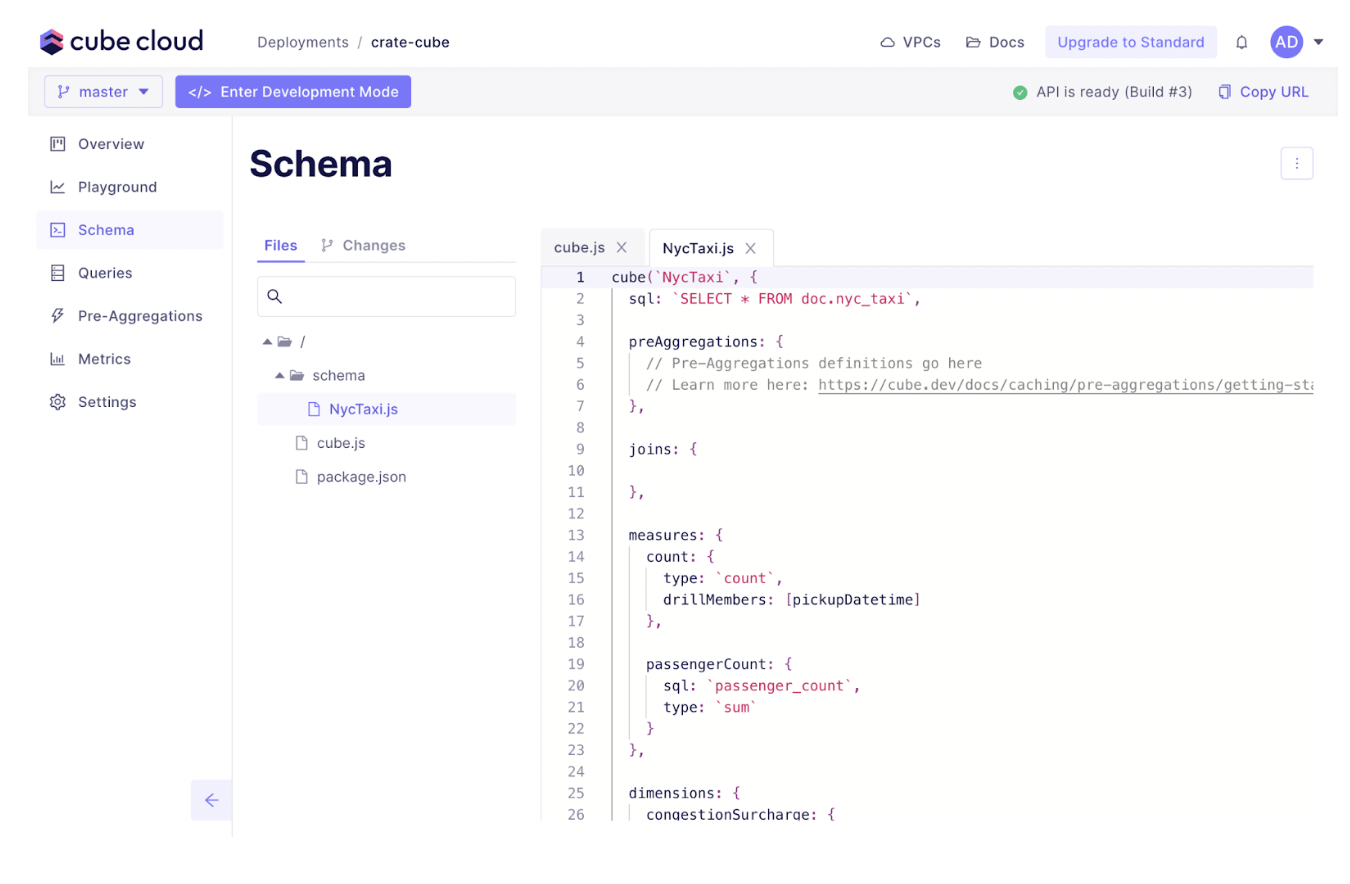
From here it's easy to add more complex measures and dimensions to create your own custom metrics layer.
Go ahead and add a custom measure.
```
totalAmountSum: { sql: `total_amount`, type: `sum` }```
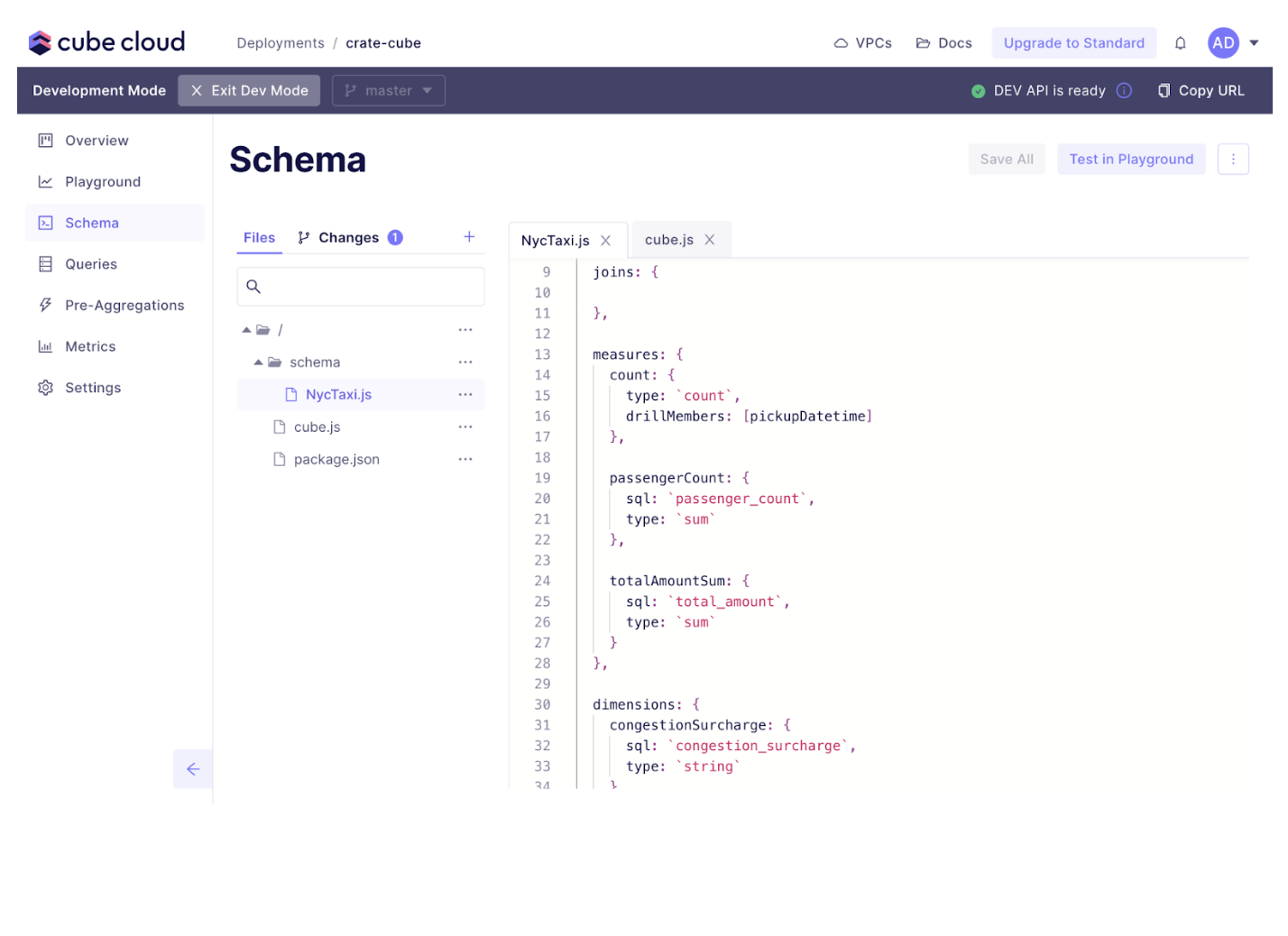
After you save and commit this change, open up the playground, and let’s run a sample query.
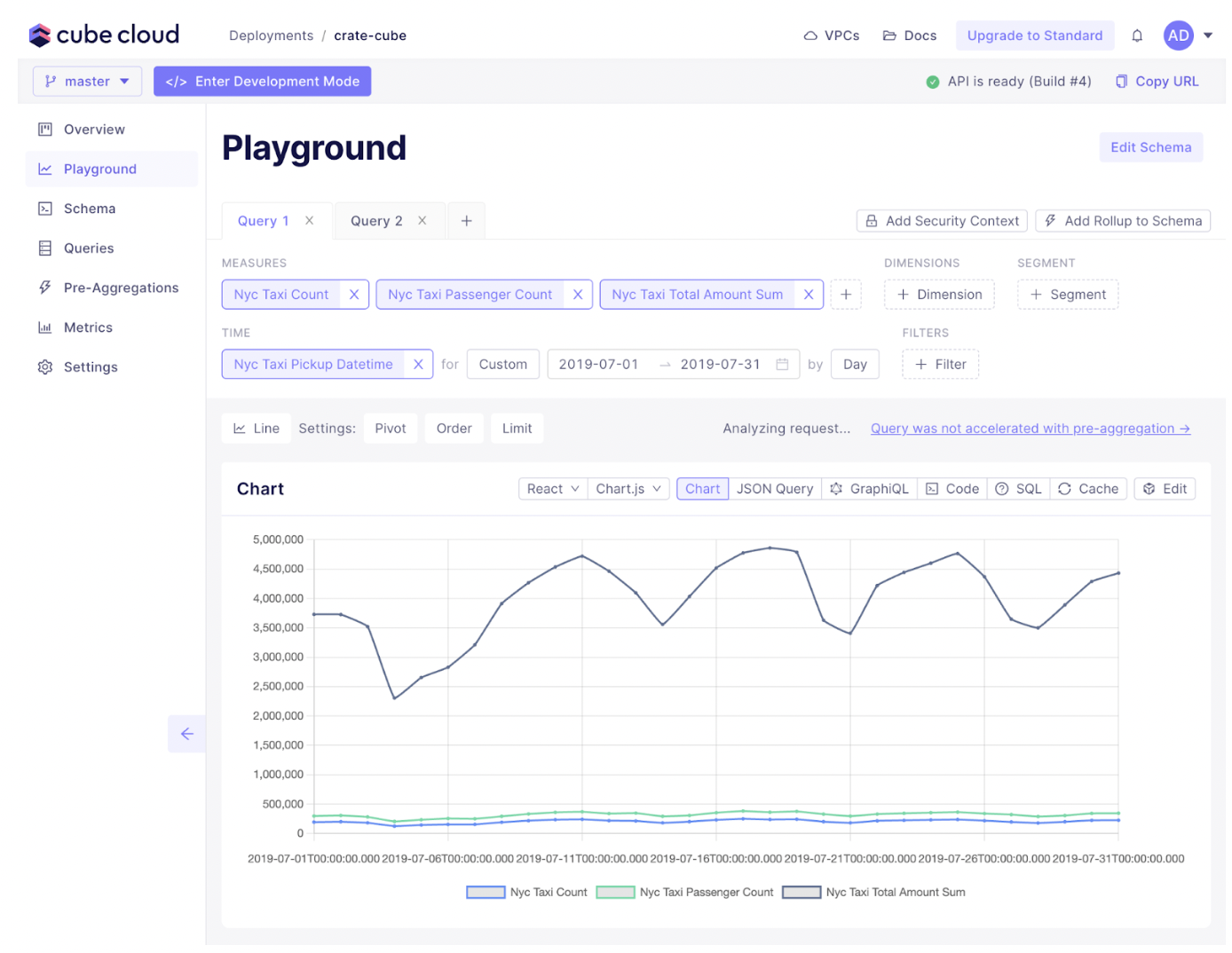
You can connect Cube to your front-end app of choice. Choose from using React, Vue, Angular, Vanilla JavaScript for the library integration, with the option to use BI tools with Cube’s SQL API.
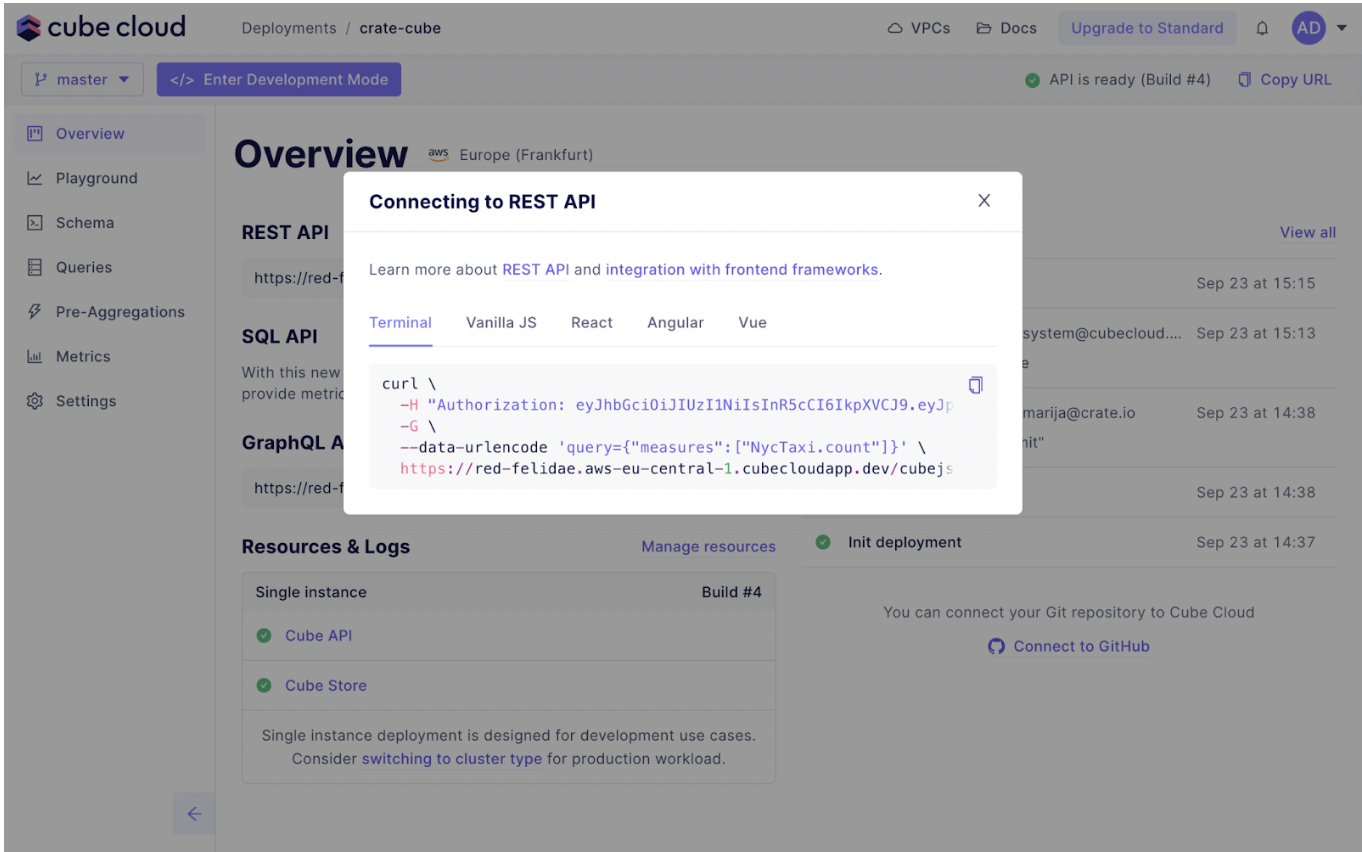
This means you can continue using all the BI tools you’re already using and are connected to your CrateDB instances. Cube only acts as the middleware layer between your BI tools and CrateDB. You still use SQL to access the data for your dashboards! Pretty neat.
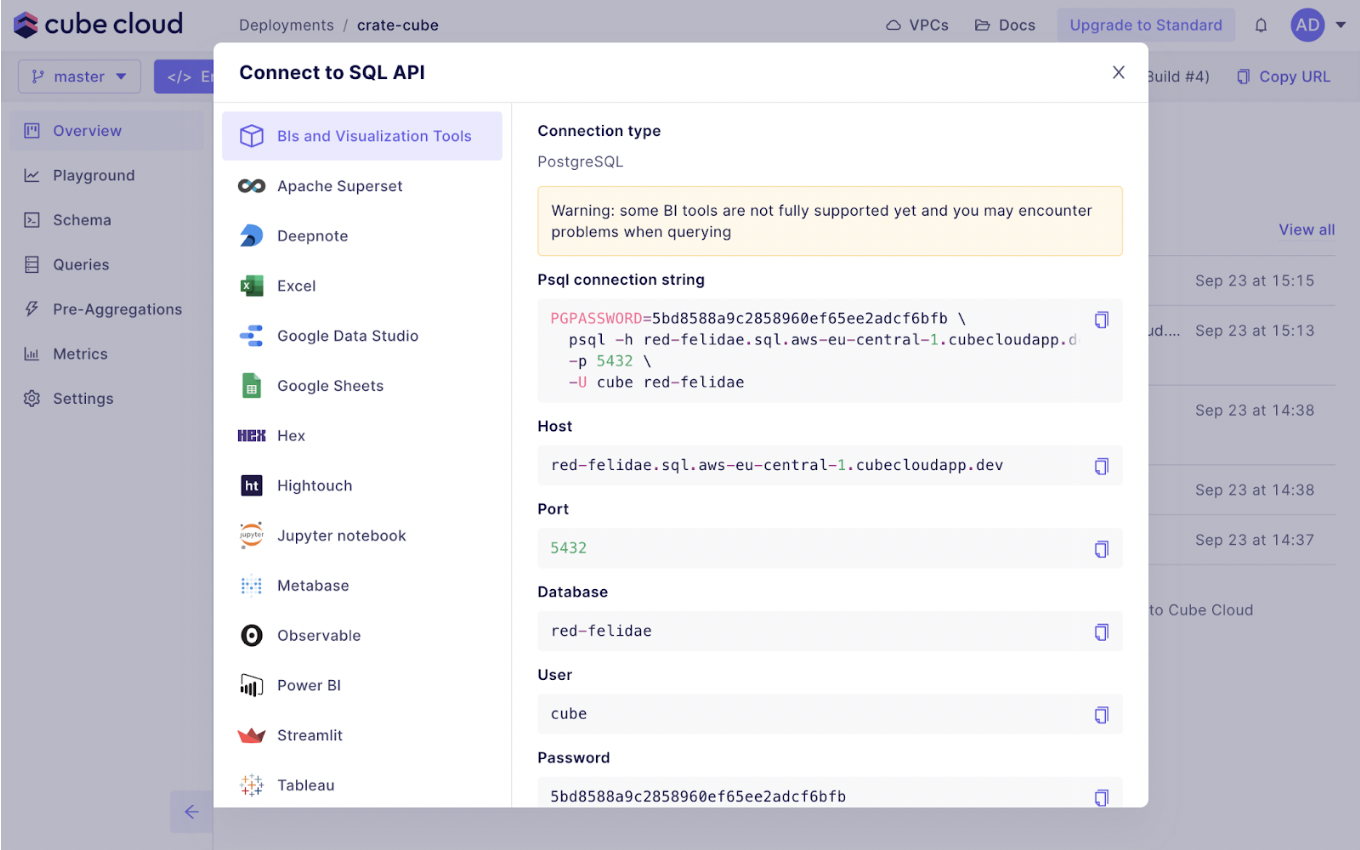
You now know how to configure Cube as a metrics layer!
Next steps
By using Cube with CrateDB in your modern data stack you get an excellent starting point for further building out your data-intensive applications.
To learn more about Cube please check our documentation and supported tools, and give it a try by registering a free Cube Cloud account today.
If you want to try out CrateDB in a few clicks and enjoy all of the CrateDB features, sign up for the CrateDB Cloud trial.
For updates, features, and other questions you might have join our Cube and CrateDB communities.