The GitHub Archive is a project that collects all the data from the public GitHub timeline, and makes it freely available and easily accessible for analysis.
At Crate.io, we have been working with the GitHub Archive dataset for a while now. It’s an amazing resource, and a very useful for source of example data for building demos.
We are at the OSCON in Austin this week, and we wanted to build a demo specifically for showing off CrateDB at our booth. (Come say hi!)
In this post I’ll show you what we built with this data and how we built it.
Basic Setup

First, we started out by importing all of the GitHub Archive data. This resulted in around 425 million data entries, taking up 265 GB on disk. This data was imported into a five node CrateDB cluster running infrastructure donated by IBM Softlayer. Each machine has 16 cores and 64 GB of RAM.
Once the data was imported into CrateDB, we teamed up with the folks from IBM Watson to do sentiment analysis on commit messages.
IBM Watson provides an API endpoint where you can post whatever text you want and it returns the analysis. You get a general sentiment (positive or negative) and confidence values for five emotions: sadness, joy, disgust, fear, anger. Confidence value is the accuracy of the emotion for the given text.
If we feed IBM Watson a commit message like “OMG, the bear is following me and trying to eat my leg.” we get back this object:
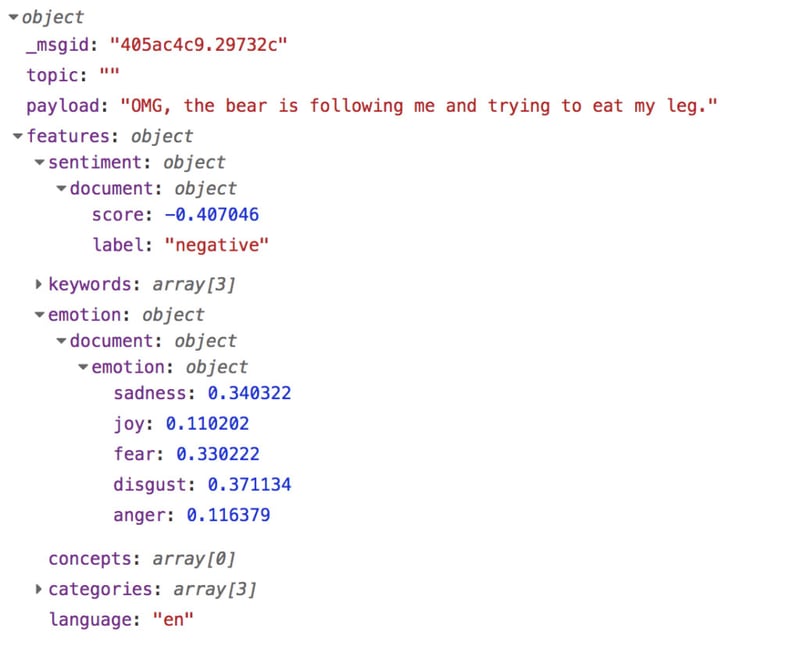
Here, you can see the general sentiment (negative) along with an emotion object with confidence values for all five emotions that IBM Watson considers.
Once we had all of that hooked up, our friends at arkulpa wrote a simple Slack bot using Node.js and Botkit Studio that allows you query the data.
Botkit Studio is a visual programming environment that makes it a total breeze to create and manage bots. You can get started creating your own bot by modifying the Bitkit starter code hosted on Glitch.
The Bot in Action
Let’s jump right in and take a look at what it looks like to interact with the bot:
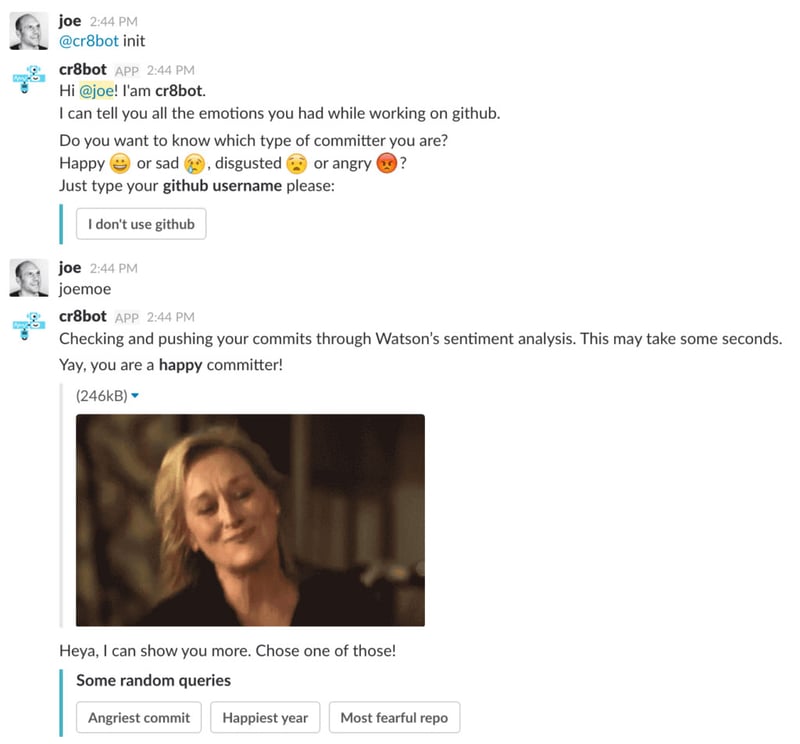
Here, I initiate the bot with the init command. Afterwards, I request a sentiment analysis of my own commit messages.
When I do this, the bot fetches all of the commit messages authored by me on GitHub and sends them to IBM Watson for analysis. Once this is done, the bot stores the results of the sentiment analysis back into CrateDB by annotating the original data.
Once we have annotated data, we can query it.
For example, here’s an aggregation query that fetches the total number of commit messages that match each type of emotion:
SELECT
SUM(if(f_watson['emotion']['sadness']>0.5,1,0)) AS "Sadness Count",
SUM(if(f_watson['emotion']['disgust']>0.5,1,0)) AS "Disgust Count",
SUM(if(f_watson['emotion']['joy']>0.5,1,0)) AS "Joy Count",
SUM(if(f_watson['emotion']['anger']>0.5,1,0)) AS "Anger Count",
SUM(if(f_watson['emotion']['fear']>0.5,1,0)) AS "Fear Count"
FROM github.event
WHERE f_commit['author'] = any(['tomsvogel']);
Here, we’re testing on a 50% confidence interval to register a commit message as belonging to the corresponding emotion.
Wrap Up
Our GitHub Archive and IBM Watson powered Slack bot demonstrates a common use pattern for CrateDB: selecting a subset of a large dataset (filtering on location, tenant, time window, user action, tracking values, and so on) and then annotating or enriching it.
Once the bot has that annotated data, it is possible to ask all sorts of other questions. For example, I can request to know my happiest month on GitHub!
And of course, being a Slack bot, it wouldn’t be complete without a load of emoticons and animated gifs. 👌
Next up: we’re thinking about porting this to Facebook Messenger. And who knows, maybe we’ll even open source the code.