In part one of this miniseries, I shared my excitement about machine learning and introduced you to things like predictive maintenance and problem formalization.
In this post, I briefly explain how machine learning fits into the larger discipline of data science and then go on to show you how to get started on a toy project using three open source tools:
- CrateDB
A distributed SQL database. - Jupyter Notebook
A web-based notebook for interactive computing. - Pandas
A data analysis library for Python.
I'm using macOS, but the following instructions should be trivially adaptable for Linux or Windows.
Let's go.
Data Science
To really make the best use of machine learning, we need to understand the problems we are trying to solve. And we need to be able to contextualize, interpret, and leverage the results that machine learning produces.
That frequently necessitates the application of statistical modeling, mathematics, data analysis, information science, computer science, and so on.
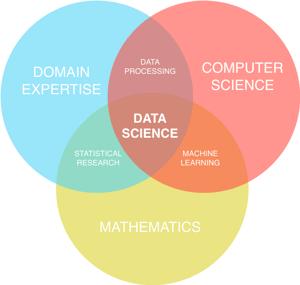
(Adapted from Data Science Venn Diagram by Shelly Palmer.)
Data science is the interdisciplinary field that brings all of these together.
But What Does a Data Scientist Actually Do?
Data scientist and author Joel Grus says that “a data scientist is someone who extracts insights from messy data.”
A data scientist might be expected to:
- Design and conduct surveys or studies
- Interpret that data
- Design data processing algorithms
- Produce predictive models
- Build prototypes and proof of concepts
And so on...
Data Science as a Process
Data science is the combination of multiple fields. But it's also important to think of data science as a process.
I particularly like this representation of the data science process:
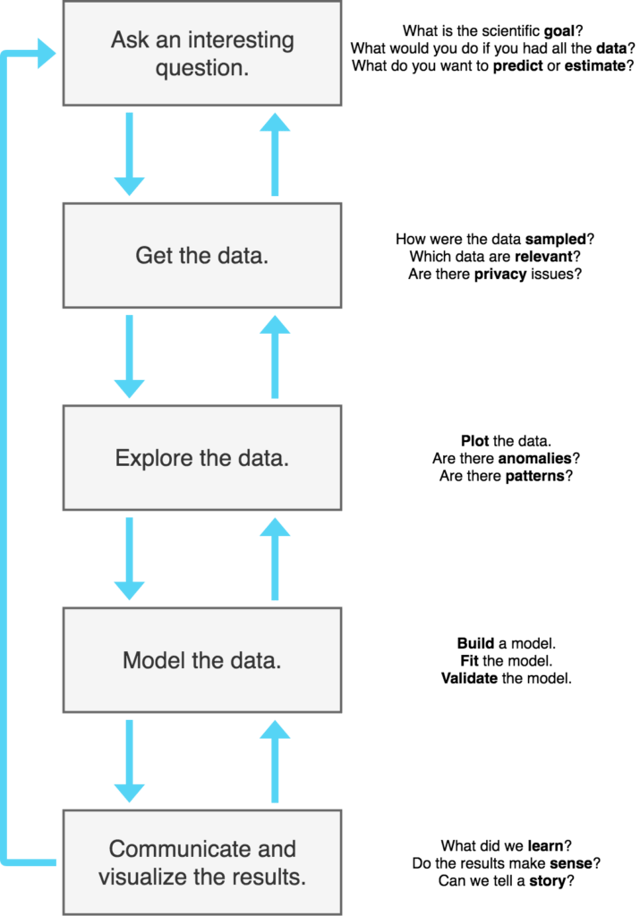
(Adapted from the Harvard CS 109: Data Science lecture slides by Hanspeter Pfister, Joe Blitzstein, and Verena Kaynig.)
As you can see from the diagram, the data science process is iterative and non-linear, and different skills are required for each step.
We often start by asking a question that needs data to answer.
From there, we collect and prepare the data, explore it, model it, interpret it, and communicate the results.
Crucially, at any stage, additional insight gained may require us to go back one step. Perhaps we need more data, or different data. Maybe we need to prepare it or model it differently. All of this can change as we understand more about the data.
Sometimes it happens that you realize the question itself was flawed, and that a different question is better.
The Science Bit
Data science is also a science.
That seems like a redundant thing to mention, but it's important to stress. Fundamentally, data scientists apply the scientific method to understand data.
Data scientists:
- Make observations
- Formulate hypothesis
- Test hypothesis
- Evaluate the results
Critically, the scientific method demands that we take a skeptical view of our hypotheses.
As Edward Teller, the famous Hungarian-American physicist, once said, a "fact is a simple statement that everyone believes. It is innocent, unless found guilty. A hypothesis is a novel suggestion that no one wants to believe. It is guilty, until found effective."
Let's Get Started
Okay, with that quick introduction to data science and how it relates to machine learning, let's set up a data science environment so you can get started.
I'm going to show you how to start playing around with data from CrateDB using the Pandas library and Jupyter Notebook.
Install CrateDB
If you don't already have CrateDB running locally, it's relatively effortless to get set up.
Pop open a terminal and run this command:
$ bash -c "$(curl -L https://try.crate.io/)"
This command just downloads CrateDB and runs it from the tarball. If you'd like to actually install CrateDB a bit more permanently, or you are using Windows, check out our collection of super easy one-step install guides.
If you're using the command above, it should pop open the CrateDB admin UI for you automatically once it has finished. Otherwise, head over to http://localhost:4200/ in your browser.
You should see something like this:
Get Some Data
If you’re playing around with a fresh CrateDB install, it's likely that you don't have any data. So head on over to the Help screen by selecting the question mark icon on the left-hand navigation menu.
The help screen looks like this:
Select IMPORT TWEETS FOR TESTING and follow the instructions to authenticate your Twitter account.
Don't worry. This isn’t going to post anything on your behalf. It doesn’t even look at your tweets. All this does is import a bunch of recent public tweets on Twitter.
Once you're done, select the Tables icon from the left-hand navigation, and then choose the tweets table. You should end up here:
http://localhost:4200/#/tables/doc/tweets
Which should look like this:
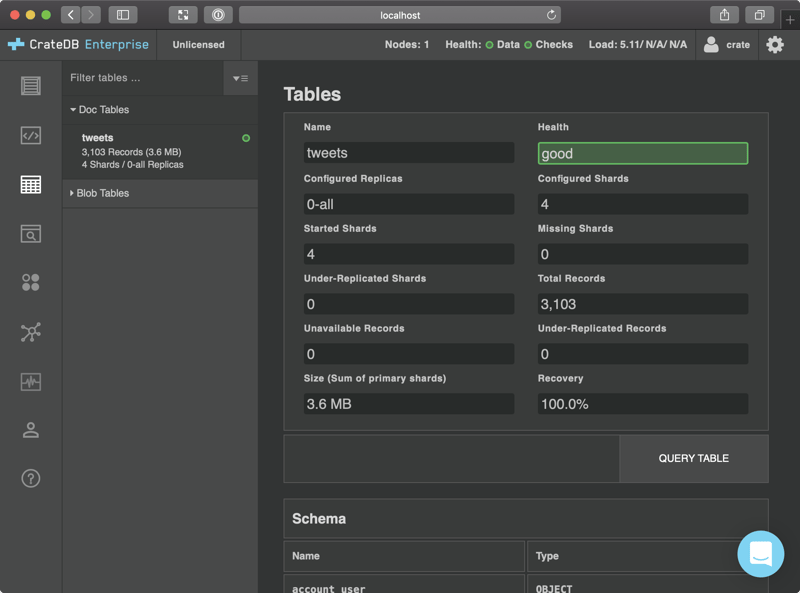
Okay, great!
We've got some tweets. Let's do something with this data.
Install Anaconda
Instead of installing Pandas and the Jupyter Notebook manually, we're going to install Anaconda, which is an open source data science platform that comes with both Pandas and Jupyter Notebook.
Head over to the Anaconda download page.
Select the Python 3.7 version.
When the download has finished, run the installer:
Select Continue and follow the instructions.
If you get asked to install Microsoft VSCode, you can just select Continue, because we won't be needing it.
When you're done, Anaconda should be installed.
Install the CrateDB Python Client Library
We're going to be using Python to access CrateDB, so before we continue, let's install the appropriate library.
Anaconda should have modified your system $PATH so that python points to the version of Python that ships with Anaconda.
Anaconda achieves this by appending a line to your ~/.bashrc or ~/.bash_profile files. You can revert back to your original Python setup at any time.
Check this worked, like so:
$ which python
/anaconda3/bin/python
Pip (the Python package manager) should also be pointing to the version that ships with Anaconda:
$ which pip
/anaconda3/bin/pip
Then, install the CrateDB Python client library, like so:
$ pip install crate
Create Your First Notebook
What do I mean by notebook?
In the context of computer science, a notebook is a sort of cross between a word processing document and an interactive shell. Specifically, Jupyter Notebook is a web application that "allows you to create and share documents that contain live code, equations, visualizations, and narrative text."
Jupyter Notebook is the successor to the IPython Notebook. IPython itself being a more feature-rich alternative to the Python interactive shell.
Start the Anaconda Navigator:
$ anaconda-navigator
You should see something like this:

Select Launch from the Jupyter box (top center).
This will open Jupyter Notebook in a new browser window:
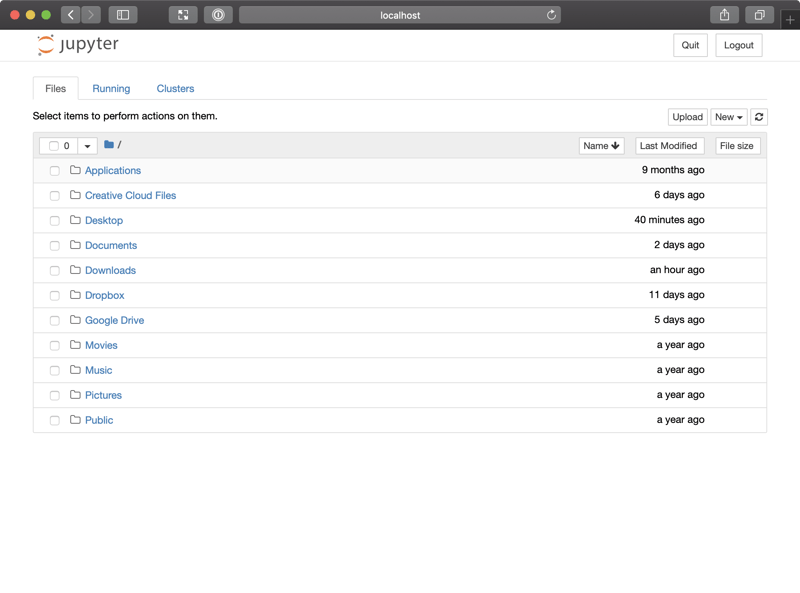
This shows a list of files in your home directory.
Typically, you would navigate to your notebook files and open them from this interface. But as we don't have any notebook files yet, let's create one.
Select New from the top right-hand navigation menu, and then Python 3, like so:
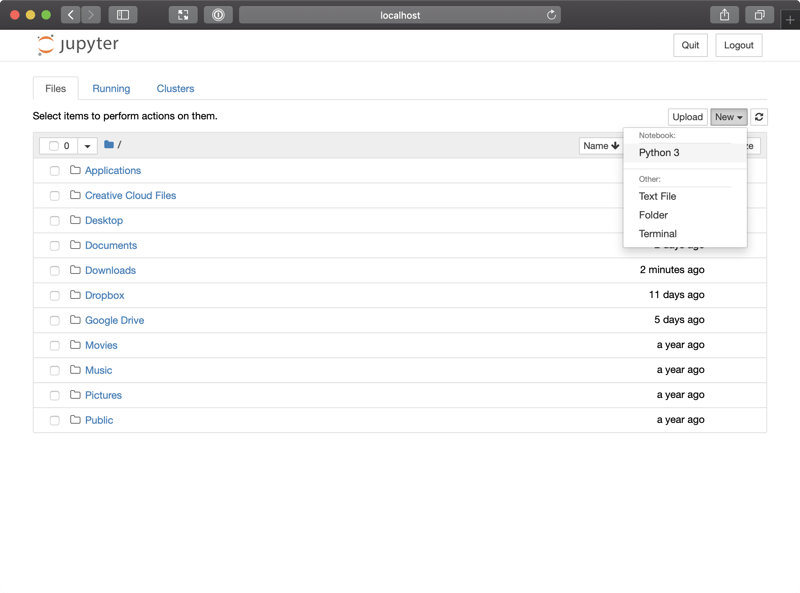
This should open a new tab with a blank notebook:
Here, you can see a box with In [ ]: (meaning "input") and then an input field.
You can type Python code into the input field:
Hover over the In [ ]: text and you should see a play icon appear. If you press this icon, your Python code will be run:
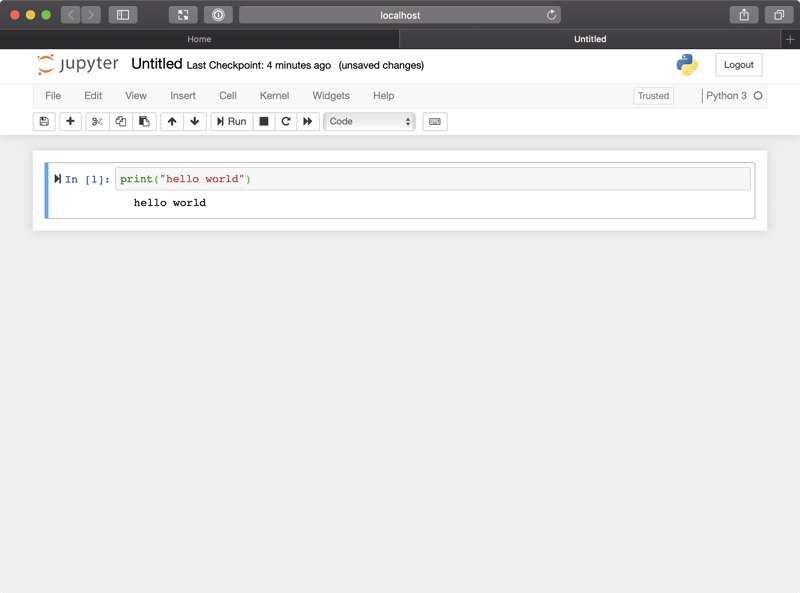
Okay, great!
Query CrateDB From Jupyter
Now we have our first notebook set up, let's import our Twitter data into Jupyter using Pandas.
Pandas is a library that "provides high-performance, easy-to-use data structures, and data analysis tools for the Python programming language."
Firstly, we need to import the pandas module.
Select the "+" icon from the top left-hand Jupyter notebook navigation menu.
A new In [ ]: box should appear:
Type the following input:
import pandas as pd
Then run the input.
Nothing should happen. That's good. It means that the import was successful and didn't raise any exceptions.
Next, let's define an SQL statement for querying CrateDB. We want to fetch all distinct users and their followers and friends.
limit = 100000
sql_query = """
SELECT DISTINCT account_user['id'] AS id,
account_user['followers_count'] AS followers,
account_user['friends_count'] AS friends
FROM tweets LIMIT {};
""".format(limit)
Again, this should produce no output:
Let's execute this statement and return the results as a DataFrame.
A DataFrame is the Pandas data structure that corresponds to a table of rows. The DataFrame includes functionality that allows us to perform various arithmetic operations on the data, as well as SQL-like post-processing operations such as aggregates and joins.
Type the following:
try:
df_data = pd.read_sql(
sql_query, 'crate://localhost:4200', index_col='id')
except Exception:
print('Is CrateDB running and are the tweets imported?')
Here, we're connecting to CrateDB on localhost:4200, executing our prepared statement, and returning the results as a DataFrame named df_data using id as the index column. If the connection or the query errors out, an exception is raised, and an error message is printed.
Again, if everything worked, there should be no output:
Now we have our DataFrame we can display it:
display(df_data.head(10))
This displays the first 10 rows:
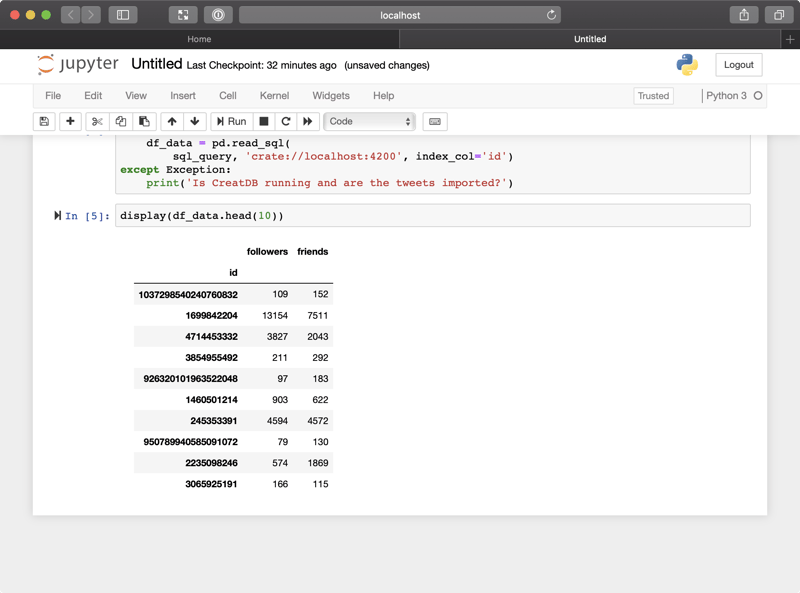
Neat!
Don't forget to give your notebook a name. Click "Untitled" at the top of the window and choose something useful.
Wrap Up
In this post, I spoke about how machine learning is one component of data science. Then I showed you how to get started with Jupyter.
From here, you might want to start poking around with Pandas to see what else you can do with the data from CrateDB.
In part three of this miniseries, I will show you how to use these tools to implement a linear regression model to predict the number of followers a Twitter user has depending on their number of friends (the people they follow).