My background is in electrical engineering and visual computing, and I have been fascinated by machine learning and artificial intelligence for a long time. Not only because of how these fields apply to visual computing, but also because of the ways they can be used with what is now commonly termed "big data." That is, the processing of data sets that are too big or too complex for traditional setups.
After four years living abroad in different cities around Europe, I finally decided to move back to Austria at the end of 2017 to start my data science master's degree at TU Vienna. Almost at the same time, I joined Crate.io. Three months ago now. And I am fortunate enough to be able to continue digging deep into machine learning and artificial intelligence here.
This is part one of a miniseries in which I will hopefully get to share a little of my excitement about machine learning with you, introduce you to the some of the fundamentals, show you how to get started with machine learning yourself with some hands-on coding, and also talk a little bit about what we're doing at Crate.io.
Crate.io
In case you didn't already know, Crate.io is building (amongst other things) CrateDB, a distributed SQL database that makes it simple to store and analyze massive amounts of machine data in real-time.
Some of our clients are using CrateDB to ingest and process 10s of thousands of sensor readings per second from hundreds of machines across multiple geographically separate production plants.
This is precisely the sort of situation that presents abundant opportunities for machine learning applications. For example, with vast quantities of time-series machine data that can be queried in real time, you can start to look at things like predictive maintenance.
Machine Learning
Artificial Intelligence (AI) has been around, in one form or another, for more than a half century. The field experienced an early surge of interest, but the hype was short-lived. Unfortunately, AI failed to live up to the promises of the early proponents.
One of the biggest obstacles to those early AI efforts was the power of the technology at the time. To put it into perspective, the same year AI was founded as a discipline, 1956, the Bendix G-15 computer was introduced. It used vacuum tubes instead of transistors, and its speed was best measured by how fast it could read punched cards.
The recent resurgence of interest in AI is massive because hardware has finally caught up with the demands placed on it by even modest machine learning applications.
Additionally, the world is now producing so much digital data, that we finally have the sorts of massive datasets that are necessary to train machine learning algorithms with.
Those gains in machine performance and the development of better techniques to make use of those gains are essential. But pragmatically, it's this explosion of data that is most exciting. Because often, the quickest path to success is getting your hands on more data and let the data do the heavy lifting.
As a rule of thumb, a simple algorithm with lots and lots of data beats a complex one with only modest amounts of data.
But I am getting ahead of myself. I apologize.
Machine Learning @ Crate.io
There are lots of ways to approach machine learning, and similarly, there are lots of libraries, frameworks, tools, platforms, and services you can use.
Microsoft Azure has a machine learning platform, as does Google Cloud, and Amazon Web Services.
Commercial platforms can be useful, especially for production applications, but it also comes with vendor lock-in. That is, if one platform isn't working out for you, it could be quite a considerable effort to rewrite your code.
In this miniseries, I'm going to keep things simple and flexible by using open source software that you can run on your personal machine. Specifically, I am going to look at Python, which has a rich machine learning ecosystem. Indeed, Python is the language of choice for many mathematical and scientific programming domains.
For example, at Crate.io, we're using Apache Spark, scikit-learn, Tensorflow, and NumPy, to name just a few of the tools that are implemented in Python or offer a sophisticated Python frontend.
We're also using an open source application called Jupyter to test, analyze, and visualize data in rich and interactive ways. Data is read from CrateDB, and the results of our work (model parameters, accuracy data, and so on) are written right back to CrateDB.
An Example: Predictive Maintenance
So, I mentioned predictive maintenance. Let's talk about that.
One of our clients, a large manufacturing company, collects millions of sensor readings from their factory equipment on a daily basis.
For manufacturing companies, any sort of machine downtime can translate into significant financial losses.
This is why many manufacturers already employ some form of preventative maintenance, which involves planned downtime and attempts to preemptively address the likely causes of breakdown or malfunction before it occurs.
Planned downtime is preferred to unscheduled downtime because you can work around it effectively without bringing production to a grinding halt.
Predictive maintenance, then, attempts not only to address what might go wrong but when it might go wrong. So that preventative maintenance is hopefully just done when necessary, reducing overall downtime.
A system that can perform predictive maintenance is more complicated to set up than regular preventative maintenance, but, in many cases, this initial outlay is recouped many times over by a more efficient and productive plant.
Luckily for me, working at Crate.io means getting my hands dirty working with clients to figure out the best way to put CrateDB and machine learning to the task. And then also working internally with our engineers to improve CrateDB so that it integrates and works better with standard machine learning tools and applications.
Let's Dive In
Okay, so machine learning is cool and works well with CrateDB. Yadda, yadda. :) How about we dive in and prepare ourselves for some practical work.
But before we go any further...
What do we actually mean when we say "machine learning"?
If you type this question into Google, you will get a thousand different answers. But there is one particular definition, given by Arthur Samuel, one of the early pioneers of machine learning, that is both concise and useful.
Samuel defined machine learning as “a field of study that gives computers the ability to learn without being explicitly programmed.”
From this, then, we can think about trying to solve various different types of learning problems.
There are a few types, but the most common and best understood type is called supervised learning.
When you're doing supervised learning, you have a (hopefully large) amount of example data that comes in the form of pairs: the input and the desired output.
If we were building a program to perform handwriting recognition, the algorithm learns how to interpret and label images with the corresponding letter just by training it on a large dataset of prelabeled images.
The goal of supervised learning is for the program to "learn" the underlying input-output relationship.
Loan Approval
Handwriting recognition is a typical example used to teach supervised learning, but another example is loan approval.
Loan approval is slightly easier to think about because it's a decision-making process that we can imagine performing manually, step by step.
In contrast, handwriting recognition is something that our visual cortex is so adept at doing for us we are typically unaware of what is going on. [Doctor's handwriting, and my own, being the exception that proves the rule, I suppose. — Ed.]
When somebody applies for a loan, it is in the bank's interest to know how likely it is that that person will pay it back.
The problem is: there's no direct way to determine this.
So what the bank does is they look at the history of loans they have made and the history of repayments and defaults. And then they combine this information with data about the debtors and attempt to find patterns.
An alternative way to think about this is that banks want to figure out how the set of input conditions relate to the output result, which makes this problem a good match for supervised learning.
Formalizing the Problem
Okay, so let's look at loan approval in a bit more detail to understand the different components of this learning problem.
We start with applicant information, for example:
- Age: 25 years
- Gender: female
- Annual salary: 40,000 EUR
- Years in job: one
- Current debt: 15,000 EUR
And so on, and so on...
If we combine this with information about the loan they took, we get:
- Data: [latex](x_1,y_1), (x_2,y_2 ), ..., (x_N,y_N)[/latex]
Essentially, this is a collection of input-output pairs, where [latex]x_N[/latex] is the applicant information and [latex]y_N[/latex] is whether the loan was paid back or not.
From here we can define:
- Input: [latex] \mathcal{x \in X} [/latex]
This is an n-dimensional vector containing the new loan applicant information.
- Output: [latex] \mathcal{y \in Y} [/latex]
Whether the bank should approve the loan or not.
- Target function: [latex]f : \mathcal{X} \to \mathcal{Y} [/latex]
The loan approval function, which is an idealized function that perfectly maps the input domain [latex]\mathcal{X}[/latex] to the output domain [latex]\mathcal{Y}[/latex].
Our problem is that we don't know what the loan approval function is. This is essential. If we knew what the function was, there would be no need to use machine learning. We could just implement the function by hand.
Of course, with a problem like this, there can never be a perfect function. What we produce instead is an approximation of the target function. Or to put it another way, a hypothesis about the target function.
We can model this as:
- Hypothesis: [latex]g : \mathcal{X} \to \mathcal{Y} [/latex]
Where [latex]g[/latex] is a function chosen from the hypothesis set to approximate the target function, i.e., [latex]g \approx f[/latex]
Function [latex]g[/latex] is (hopefully) improved upon iteratively as the learning algorithm trains on new data.
It is this approximation function that the bank uses to approve or reject a loan application.
Ultimately, it is the goal of any supervised learning that function [latex]g[/latex] approximates function [latex]f[/latex] (the idealized function) well enough to be useful.
Here's a graphical representation of the overall process:
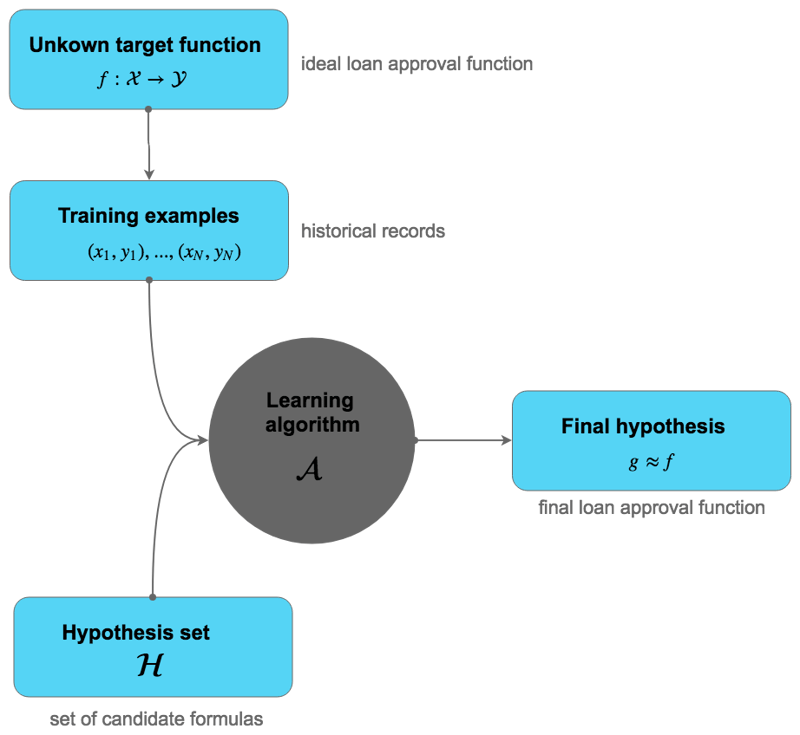
Our tools are the learning algorithm and the hypothesis set. It's critical that these two things are controlled and selected to maximize our chances of producing a well-approximated hypothesis.
Unfortunately, in many cases, training data is a fixed quantity and can’t easily be improved.
Wrap Up
CrateDB is a distributed SQL database that can be used to process massive amounts of machine data and query it in real time. This makes it a particularly ideal database for machine learning applications.
Fortunately, machine learning is more accessible today than it has ever been. And there are plenty of open source tools you can download and start experimenting with on your personal machine.
In the second post of this series, I will show you how to use scikit-learn and linear regression to train a simple model using sample data.