Testing is an integral component of software development, especially when you develop a database that is used by developers to store millions of records. That is huge a leap of faith!
We've already written about test driven development with Crate some time ago. This time we will look at how we test Crate internally and how it influences our development process. The post will cover both aspects of unit testing and integration tests.
Unit Testing
Writing Unit Tests with JUnit
If you are new to Java unit testing, you probably want to take a look at the test framework JUnit first. A super basic example of a test case could be:
public class AwesomeCrateClass {
public Boolean myMethod(Boolean value) {
return !value;
}
}
import org.junit.Test;
import static org.junit.Assert.*;
public class AwesomeCrateClassTest {
final static AwesomeCrateClass myClass = new AwesomeCrateClass();
@Test
public void testMyMethod() throws Exception {
Boolean inputValue = true;
Boolean outputValue = myClass.myMethod(true);
assertTrue(inputValue == false);
assertEquals(inputValue, false);
}
}
We at Crate.io use unit tests to test discrete functionality of components throughout the code base.
For example, for a recent feature, we had to evaluate an input string, if it is contained in a set of possible allowed values. The StringSetting class has an attribute allowedValues which is of type Set<String> and a method validate which takes a String as its input value. It should return null if the set of allowedValues contains the input value, otherwise it should return a message of type String.
package io.crate.metadata.settings;
import com.google.common.base.Joiner;
import org.elasticsearch.common.Nullable;
import org.elasticsearch.common.settings.Settings;
import java.util.Set;
public abstract class StringSetting extends Setting {
protected Set allowedValues;
protected StringSetting(Set allowedValues) {
this.allowedValues = allowedValues;
}
@Override
public String defaultValue() {
return "";
}
@Override
public String extract(Settings settings) {
return settings.get(settingName(), defaultValue());
}
/**
* @return Error message if not valid, else null.
*/
@Nullable
public String validate(String value) {
if (allowedValues != null && !allowedValues.contains(value)) {
return String.format("'%s' is not an allowed value. Allowed values are: %s",
value, Joiner.on(", ").join(allowedValues)
);
}
return null;
}
}
The actual test looks like:
package io.crate.metadata.settings;
import com.google.common.collect.Sets;
import org.junit.Test;
import static org.junit.Assert.*;
public class CrateSettingsTest {
@Test
public void testStringSettingsValidation() throws Exception {
StringSetting stringSetting = new StringSetting(
Sets.newHashSet("foo", "bar", "foobar")
) {
@Override
public String name() { return "foo_bar_setting"; }
@Override
public String defaultValue() { return "foo"; }
};
String validation = stringSetting.validate("foo");
assertEquals(validation, null);
validation = stringSetting.validate("unknown");
assertEquals(validation, "'unknown' is not an allowed value. Allowed values are: bar, foo, foobar");
}
// ... more tests here ...
}
Mocking
However, very soon you'll come to a point where you can assert that a given input matches an expected output, because the output is determined by an external source, e.g. a library you depend on. In our case, this could be functionality from the ElasticSearch or Lucene libraries. Setting up a complete environment for such test cases would not be worthwhile or is not even possible sometimes (e.g. testing output that comes directly from the operating system).
This is where mocking comes into play. Mocking allows to mock return values from sources that are either not directly accessible or controllable. We at Crate.IO use the mockito framework because of its clean and simple API.
Let's take a look at an actual implementation how mocking can be used to simulate return values from the Sigar library that usually come directly from the operating system.
Due to the extensive usage of guice we can easily mock single components/classes of dependencies for tests what would hardly be possible otherwise.
In order to inject the mocked dependency instance the test case class includes a concrete implementation of a Module. The ReferenceResolver then uses the bound instances that are mocked in the test setup phase. The resolver is later used in the test to obtain various SysObjectReferences. The actual mocking takes place in the configure method of the module:
OsService osService = mock(OsService.class);
OsStats osStats = mock(OsStats.class);
OsStats.Mem mem = mock(OsStats.Mem.class);
when(osStats.mem()).thenReturn(mem);
when(mem.actualFree()).thenReturn(byteSizeValue);
when(mem.actualUsed()).thenReturn(byteSizeValue);
when(mem.usedPercent()).thenReturn((short) 22);
when(mem.freePercent()).thenReturn((short) 78);
bind(OsService.class).toInstance(osService);
We can see that return values of methods - ones that are used by the implementation of SysObjectReferences - are mocked.
childImplementations.put(FREE, new MemoryExpression(FREE) {
@Override
public Long value() {
return osService.stats().mem().actualFree().bytes();
}
});
childImplementations.put(USED, new MemoryExpression(USED) {
@Override
public Long value() {
return osService.stats().mem().actualUsed().bytes();
}
});
childImplementations.put(FREE_PERCENT, new MemoryExpression(FREE_PERCENT) {
@Override
public Short value() {
return osService.stats().mem().freePercent();
}
});
childImplementations.put(USED_PERCENT, new MemoryExpression(USED_PERCENT) {
@Override
public Short value() {
return osService.stats().mem().usedPercent();
}
});
The test then can assert equality of the return values.
@Test public void testMemory() throws Exception { ReferenceIdent ident = new ReferenceIdent(SysNodesTableInfo.IDENT, "mem"); SysObjectReference mem = (SysObjectReference) resolver.getImplementation(ident); Map<String, Object> v = mem.value(); assertEquals(12345342234L, v.get("free")); assertEquals(new Short("78"), v.get("free_percent")); assertEquals(12345342234L, v.get("used")); assertEquals(new Short("22"), v.get("used_percent")); }
In general you should try to test single components as encapsulated as possible. There is a tendency to miss edge cases if a single test covers multiple functionalities at once. And keep in mind that there are still integration tests.
Integration Tests
We usually talk about integration tests when there is a running instance of Crate involved in the test. These mostly cover end user exposed functionality – creating, querying, altering and deleting data using SQL. This of course implies that no mocking is involved.
We use two different types to test Crate: Java integration tests, due to the nature that Crate.IO is written in Java, and Python integration tests, because they give us some great advantages I will look at later on.
Java Integration Tests
One requirement for integration tests is that the Crate instances which the tests run against need to start up before the test and shut down after the test automatically. Setting up and tearing down the test environment can be a quite tricky.
For Crate we have a base class the provides that functionality. Since the cluster setup is the same as the one from ElasticSearch we are able to reuse their great test setup and extend the ElasticSearchTestCase.
Whenever we need to write an integration test now, you simply inherit from that class.
@CrateIntegrationTest.ClusterScope(numNodes=2, scope=CrateIntegrationTest.Scope.SUITE)
public class CrateIntegrationTest extends CrateIntegrationTest {
@Test
public void testSomething() throws IOException { ... }
}
Additionally the ClusterScope decorator defines its scope and the number of nodes the test cluster should start. We have three scopes:
- GLOBAL ... a globally shared cluster
- SUITE ... a cluster shared across all methods in a single test suite
- TEST ... a cluster exclusive for a single test method
Test Cluster
The TestCluster manages a set of JVM private nodes and allows convenient access to them. The cluster supports randomised configuration such that nodes started in the cluster will automatically load asserting services tracking resources like file handles or open searchers.
Randomized Test Settings
To guarantee a comprehensive coverage of your code the cluster configuration is randomized. Every time you run an integration test it will generate a unique random seed that is used by the randomization. If a test fails with a certain seed you will be able to reproduce exactly the same test settings using the same seed again. An example of randomization is for example the encoding.
What we’ve looked at so far is all good, but nothing special. However, the problem with integration tests written in Java is that they do not satisfy our need for a documentation that works both as documentation and integration test.
Documentation Written As Integration Tests
Take some time and take a look at our documentation. All the pages that you see there, with all the code examples, are actually integration tests that pass when you run them. That ensures that their integrity is given at any time and that the documentation for different versions is always accurate.
To achieve this we have integration tests that are written as doctests – a Python module for testing textual documents. This type of tests in conjunction with ReStructuredText gives you the possibility to deploy them as rendered HTML using the Sphinx documentation generator.
The original doctest distribution allows testing of python code – however to be able to evaluate SQL statements directly you’ll have to add some custom code to parse the input. Other than that, this test setup has the same requirements (such as starting/stopping nodes) as writing them in Java directly.
Evaluate SQL Statements in Python Doctests
The doctest module lets you define your own command parser. This is the part in the code block that starts with a certain prefix and is followed by the command input. The next line is the expected result which should match the output of the evaluated input.
The parser takes the SQL statement after the cr> prefix and executes it using our own Crate Shell (aka Crash, which is by the way also written in Python).
Let’s look at the tests.py file where everything comes together.
from crate.crash.command import CrateCmd
cmd = CrateCmd()
def crash_transform(s):
return ('cmd.onecmd("""{0}""");'.format(s.strip().strip(";")))
crash_parser = zc.customdoctests.DocTestParser(
ps1='cr>', comment_prefix='#', transform=crash_transform)
def test_suite():
suite = unittest.TestSuite()
s = doctest.DocFileSuite('testfile.txt',
parser=crash_parser,
setUp=setUp,
tearDown=tearDownDropQuotes,
optionflags=doctest.NORMALIZE_WHITESPACE |
doctest.ELLIPSIS)
s.layer = empty_layer
suite.addTest(s)
return suite
Having the test suite set up this way we can write for example in the doctest file.
Select id and name from the ``sys.cluster`` table::
cr> select id, name from sys.nodes;
+-...---+-------+
| id | name |
+-...---+-------+
| ... | crate |
+-...---+-------+
SELECT 1 row in set (... sec)
The same way we also use for example the sh$ prefix for bash commands.
Hooking up the test execution to the Java based workflow is easy then. We have a Gradle task for the test run in ./docs/build.gradle that simply bootstraps the Python environment and invokes the script that start the test runner.
task itest (type:Exec){
executable = "$projectDir/bin/test"
}
It is then executed like any other Gradle task.
./gradlew itest
Using this setup described above implies that all the code examples that you find in the documentation are executable and do pass as integration tests. This will verify that the documentation is correct at any point.
When adding new features we even write the documentation ahead of the implementation to ensure the final implementation will match the expected results.
Automated Testing
Another aspect of our testing setup are automated tests. On the one hand we use Travis CI, that invokes a test run whenever someone commits to the repository. Due to the tight integration into Github you can see test results directly on Github and warns you if the code of a pull request does not pass the tests.

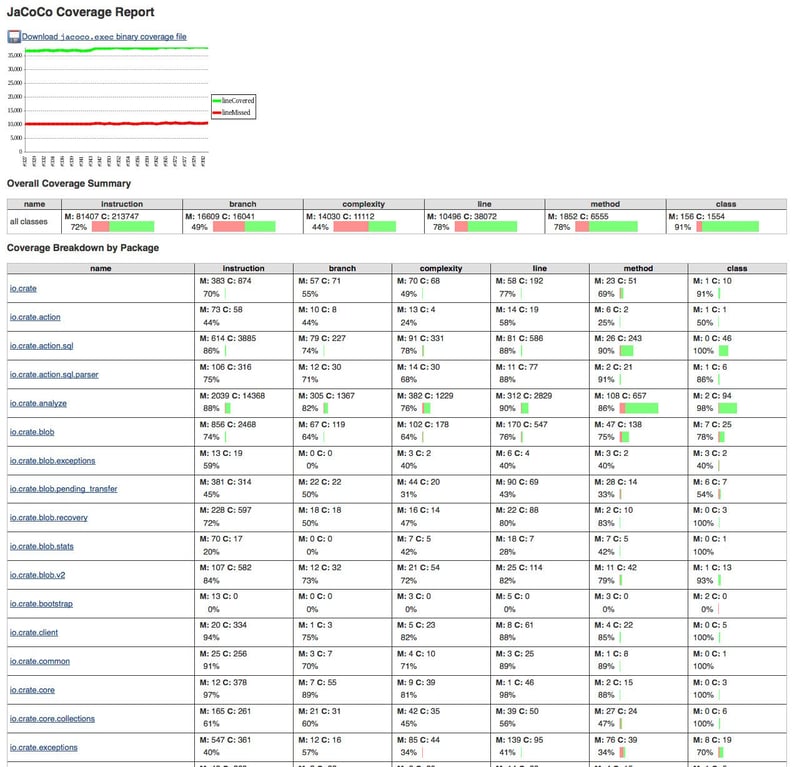
Additionally we have configured a webhook to trigger a test run on our Jenkins server to monitor the test coverage of our Java tests with JaCoCo.
Summary
We at Crate.io use unit tests to test encapsulated parts of our own code base. The more concrete the better. Mocking helps us to emulate otherwise non-deterministic or not testable units. These are usually parts where our own code interacts with its dependencies. Dependency injection with guice makes it even easier to achieve that.
We use Java integration tests to test cluster behaviour in a randomized environment. The test cluster is started in the same JVM instance as the test case and can therefore be controlled directly in the setup and teardown phase of the test.
Our documentation is written as Python doctests so it can be executed and verifies its integrity at any point.
And last but not least: Automated testing does help us to maintain code quality during the development process.
What are your thoughts on continuous testing? Let us know!