We recently compared how MongoDB, TimescaleDB, and CrateDB perform when implementing an industrial IoT use-case. In this blog post, we talk about our experience as developers working with different databases.
Objective
We wanted to see how the different databases performed for the same budget, around 5,500 $/month, when implementing an industrial IoT use-case. While still important, our main focus was not the query/insert performance like in most database comparisons. Instead, we wanted to discuss the cost-efficiency of the different options, together with finding out the advantages and disadvantages that are perhaps less evident. The results would give an honest overview of where our product (CrateDB) stands compared to the competitors, showing us where to improve.
The use-case
We simulated an industrial IoT use-case: A company with 100 plants across the world wants to build dashboards to monitor the status of the equipment used in their plants. Each plant consists of five lines with five edges per line and two sensors per edge (one float one bool), totaling in 2500 edges and 5000 sensors. The sensor values are saved in a database every half second, resulting in 10000 collected metrics per second. We wanted to run all our tests on a prepopulated database, to measure how the database behaves while being already under load. We decided on populating the database with two weeks of data, which translates to 12 billion metrics. Another important requirement was to not use randomly generated values, but a dataset that behaved as close to a real-world industrial IoT use-case as possible.
Dataset
For this use-case, no dataset existed with enough values, and copying values was not an option since they wouldn't reflect real-world data. We needed to find a way to insert a comparable dataset in all databases. We finally decided to base our dataset on a smaller one (about one million rows). With a little python magic (import statistics) we got the statistical model from the underlying dataset (standard deviation, mean, variance). Then, with a lot more python code, we created a data generator able to turn those statistical models into many more values. As all the databases are hosted on Azure, our goal was to deploy the data on Azure and to make it scale-out. That way, we could deploy multiple instances of the data generator and still get a consistent dataset in the database.
Setup
CrateDB
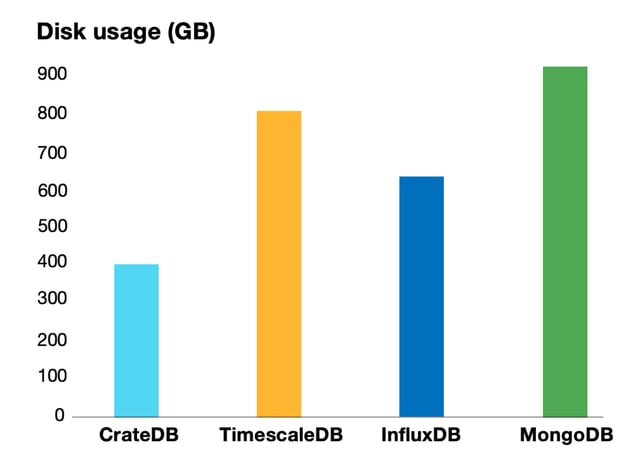
With our budget of $5,500 and our use-case set out, we chose the CrateDB General Purpose 3 cluster. In order to stay flexible with the schema in case we needed to change something later, we decided to use CrateDB’s Dynamic Object columns. We also configured a replica of the of the table to ensure data safety, representing better a real-world scenario. With 5 data generators running in parallel, we were able to insert about 260,000 metrics per second. After ingestion, the data took about 400GB of disk space, including indices. In CrateDB, indices are created automatically.
MongoDB
We set up MongoDB using their M60 tier with an adjusted Storage size of 4TB. The final price was $5,810 per month. We could not use MongoDB in a distributed cluster because the cost of the tier raised considerably, exceeding our budget limitation. Using 5 data generators in parallel, we were able to insert about 200,000 metrics per second. When the data was ingested, the Collection took about 920GB. The default index that was created took another 77GB... This already exceeded the RAM of the M60 tier. Following the suggested schema design for time series datadid not improve the situation: the additional querying required to update and insert in each document took far longer than the 0.5 second interval between sensor updates in our use case. The alternative, caching the values and writing each minute, would in turn violate our use case's monitoring requirements.
TimescaleDB
At the time this comparison was done, there was only a single-node version of TimescaleDB available. The plan we used was the Pro-io-optimized Cluster with 2TB of disk, 8 CPUs, and 64GB of RAM. The price was $5,380 per month. To get as close as possible to the Dynamic Object columns of CrateDB, we initially used JSON columns. However, we soon realized that it would take us way longer to insert all the data… And queries were way slower than with CrateDB. We switched to “normal” top-level columns. Running 20 data generators in parallel we were able to insert about 200,000 metrics per second. In the case of TimescaleDB, we needed 20 data generators instead of 5, due to the slow performance of psycopg2. As query execution time was still slow, we asked support from the awesome people from TimescaleDB, since we really wanted to have a non-biased result. They supported us in creating an optimized index for the query. In the end, the dataset took about 800GB of disk space, and the index another 100GB.
InfluxDB
In the case of InfluxDB, we chose their usage-based plan since we couldn’t make a yearly subscription. The costs of the plan are the following:- Data-in: $0.0015/MB
- Query-duration: $0.0015/s
- Storage: $0.0015/GB-hour
The usage-based plan came with an additional write limitation of 300MB over 5 minutes. This meant that we were only able to insert about 15,000 metrics per second. It took over a week to insert all metrics, and the data ended up taking about 620GB of disk space. In the case of InfluxDB we found it difficult to predict how much the use-case would cost, due to the particularities of the usage-based plan. We could only project a monthly cost of about $3,000, but that was excluding queries, and ignoring a growing dataset (although InfluxDB offers good data retention automation).
Queries
Even though it wasn’t our main focus we still needed to compare query times, to know if we were getting a comparable performance from the different databases. We chose a query showing the average value of the float sensor over the last 15 minutes for one hour, as this would be something interesting to see on a dashboard. The resulting query in SQL looked something like this:To run the queries, the following setup was used:
- 10 clients concurrently
- 1 million query execution
- Alternating timeframes, plants, and sensors
- Data generator inserting 10,000 metrics per second while queries are run
- One run with a timeframe of one hour and one with a timeframe of 24 hours
- Execution and result tracking with JMeter
This figure shows the percentile values for 50% and 99% of the queries:
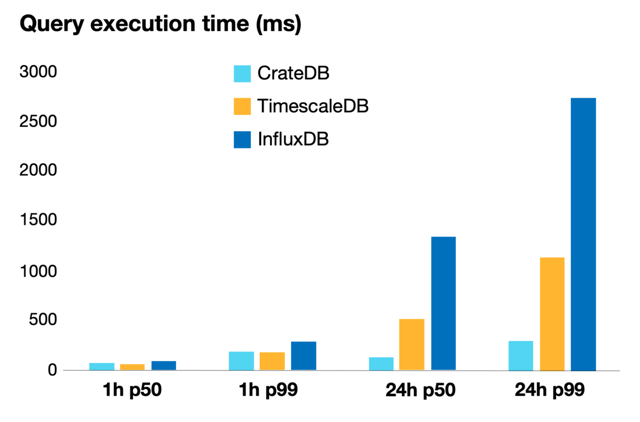
As you can see, MongoDB is missing from the chart. This is because it was not possible to execute a similar query in MongoDB (even using the indices suggested by the MongoDB Query Profiler), as one execution took 34 seconds on average, and we needed 1 million. For the 1-hour query, TimescaleDB was a little faster (10 ms) than CrateDB. However, TimescaleDB was more than 500 ms slower when extending the time range to 24 hours. Besides, for TimescaleDB we needed to create an index, whereas no special configuration was needed for CrateDB. In the case of InfluxDB, it could keep pace for the 1-hour timeframe. However, it got significantly slower for the 24-hour timeframe. This could be due to the limitations of the usage-based plan.
Conclusions
MongoDB
In our experience, MongoDB was not the best fit for our use-case, i.e. an Industrial IoT use-case that required cost-efficiency. The main problem we found is that MongoDB indices should fit into RAM, but even the default index already exceeded the RAM limits. In order to have enough memory for the default index and one additional one, it was necessary to pay for at least the Tier M140. This would drive up the cost considerably, and still, it won’t be providing enough speed for other queries. Despite not being a good match for our use-case, we still loved the CloudUI and all the possibilities it offered, such as the Query Profiler, Index Suggestions, Realtime System Usage Overview, Metrics …
TimescaleDB
TimescaleDB showed very good performance, and their customer support was very effective in helping us setting up the index for our query so we could get non-biased results. The most important problem with TimescaleDB was that only four weeks of running the use-case would fill up the disks (or with 10 indices, in two weeks). Upgrading to the next plan instantly implied doubling the costs, even though in our case we only needed more disk space.
InfluxDB
InfluxDB offered one of the best CloudUIs, with an incredibly cool Data Explorer and settings for data retention per bucket. However, we found several errors in the documentation, and in the case of InfluxDB this is important–since having a proprietary query language (FLUX) implies that there are not a lot of support sources outside their documentation. InfluxDB also had the slowest query performance, running up to nine times longer if compared to CrateDB.
CrateDB
CrateDB offered the best result for the use-case. It showed a very good query performance over a large timeframe while being easy to setup (no indices had to be created by hand), staying very cost-efficient. Besides, CrateDB offered the largest disk space for the same price. This makes larger use-cases easier to run on a budget. With the other databases, in order to ingest more data or to improve performance, the cost would easily double or triple.