After two years in preview, Amazon Timestream is now out in the world.
Timestream is Amazon's new offering for time-series data, aimed to target IoT use-cases, DevOps, and analytics apps. They promise a performance up to 1,000 faster than relational databases for 1/10th the cost. They also offer the possibility to easily query and store hot and cold data, with automatic scaling, simple accessibility, and (of course) specific time-series functions: on-the-fly aggregations, window functions, and arrays.
With the goal of testing how CrateDB stands in comparison with the other databases in the market (you can read about our previous comparisons here and here), we gave Amazon Timestream a try. As developers, we were also very curious to be able to finally check it out.
In this blogpost, we summarize both our impressions and the data we collected, comparing how both CrateDB and Timestream perform against a heavy IoT workload. More specifically, we simulated an industrial IoT use case - just as we did when we tested MongoDB, TimescaleDB and Influx.
We were especially curious to know:
- How fast AWS Timestream can insert data
- How much storage is consumed by that data
- The query speed
- The monthly costs
Let's get into it.
The use case
Since CrateDB is a database strongly focused on industrial use cases, we simulated an industrial IoT project, as we usually do in our comparisons:
- Our virtual industrial company has 100 plants across the world, with dashboards monitoring the status of their equipment
- There are 5 production lines in every plant, with 5 edges per line and 2 sensors per edge. This makes a total of 2500 edges and 5000 sensors
- The sensor values are collected two times per second, which results in 10,000 metrics per second in the database
- To measure how the database performs when it is already under load, we pre-populated it with two weeks’ worth of data (12 billion metrics)
AWS Timestream: setup and pricing
AWS Timestream still does not offer different tiers of deployments, so to set it up was easy: we simply created a Service.
Their pricing is based on usage:
- Writes: 0.50 USD / 1 million writes of 1KB size
- Storage:
- Memory: $0.036 / GB/hour
- Magnetic: $0.03 / GB/month
- The price of writing SSD Storage is not yet available
- Query: 0.01 USD / GB scanned
- Data Transfer: no price listed
Data ingest
As we said before, it is important to populate the database with data before starting the ingest, in order to get an accurate representation of its performance in the real-world.
To populate AWS Timestream with the 12 billion metrics, we added AWS Timestream support to our data generator by converting the existing JSON Object to the AWS Timestream format, which consists of 'Common Attributes' and 'Records':
JSON object{
"timestamp": 1600000000000,
"sensor_id": 1,
"line": 0,
"plant": 0,
"temperature": 6.40,
"button_press": False
}
AWS Timestream format:CommonAttributes:{
"Dimensions": [
{"Name": "plant", "Value", "0"},
{"Name": "line", "Value": "0"},
{"Name": "sensor_id", "Value": "1"}
],
"Time": "1600000000000"
}Records:[ "MeasureName": "temperature", "MeasureValue": "6.40", "MeasureValueType": "DOUBLE" }, { "MeasureName": "button_press", "MeasureValue": "False", "MeasureValueType": "BOOLEAN" }
An immediate issue we found is that there was a quota limiting the insert to 100 records per insert. This required additional logic to the code, also reducing the batch insert benefits.
With this setup, it was possible to insert approximately 600 metrics per second into AWS Timestream, from a single client. In comparison, we inserted ~52,000 metrics per second into CrateDB, also from a single client and with the same setup.
Trying to improve AWS Timestream ingest speed, we run it a second time. We split the data generator into 20 instances running in parallel directly in AWS. With this setup, we achieved ~10,800 metrics per second. This corresponds to an average of ~540 metrics/s per client.
Queries
After 3 days of data ingestion, our dataset already consisted of about 2 billion metrics, and we decided to try out some queries.
To run the queries, we used a similar setup than last time:
- 10 concurrent clients
- 10,000 query executions
- We queried data on memory storage
- One query run with a timeframe of 1h and another with a timeframe of 24h
- We did the execution and result tracking with JMeter
The query for Timestream looked like this:
WITH binned_metrics AS(
SELECT
avg(measure_value::double) as avg_value,
bin(time, 15m) as minute_slot,
bin(time, 1h) as rounded_hour
FROM test.temperature
WHERE
sensor_id = '535' AND
time BETWEEN '2020-10-10 09:00:00' AND '2020-10-10 10:00:00'
GROUP BY
bin(time, 1h),
bin(time, 15m))
SELECT rounded_hour, minute_slot, avg_value
FROM binned_metrics
ORDER BY rounded_hour, minute_slot
(To review the CrateDB variants of the query, check out our previous comparisons - here and here).
The results we got are summarized in the table and figures below, showing the percentile value for 50% and 99% of the queries:
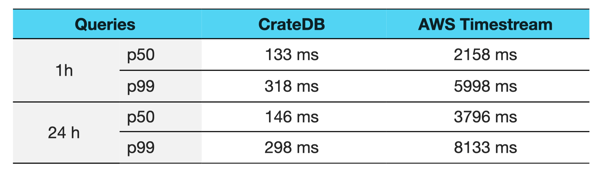
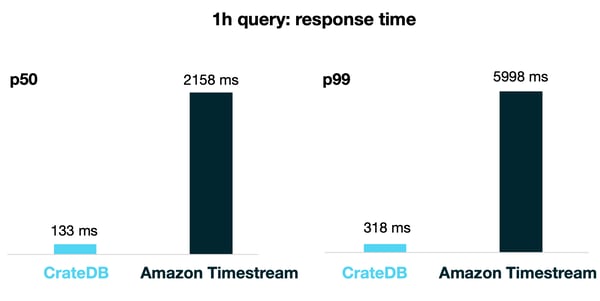
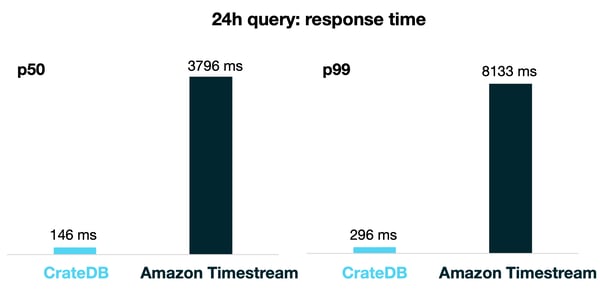
In these aggregation queries, CrateDB outperformed AWS Timestream: CrateDB was 10x faster in the 1h query and 20x faster in the 24 query!
Costs
To wrap our analysis up, let's take a look at the cost.
As we said before, AWS Timestream pricing is based on usage. However, AWS does not break it down, and it is difficult to know how the total cost is going to be calculated. To take a guess, we limited the cost calculation to single days, using only one part of the service and therefore getting an insight into how each aspect contributes to the final costs.
We deduced that for our use case:
- To insert data cost around +40 USD per day
- To query data cost around +30 USD per day
With respect to the storage costs: AWS Timestream does not tell you how much storage you're using, so to discuss storage costs is also difficult. But assuming that one year's worth of data is stored, and even assuming that AWS has similar storage requirements as CrateDB, we'd get 10.4 TB of data. This would add another +312 USD per month to the bill.
With the insights we have, the total cost of this use case in AWS Timestream is 2500 USD/month. This is way cheaper than other databases in the market, including CrateDB, which costs around 5,300 USD/month for this use case.
Our thoughts
As they promise, AWS Timestream is cheaper than other databases. This is clearly a strong point. However, AWS Timestream doesn't seem a database mature enough for large-scale IoT use cases like the one we tested.
Timestream's insert and query speeds are between 10x and 20x slower than in CrateDB. Additionally, it doesn’t' offer built-in backup compatibilities, which results in extra engineering work and, possibly, extra costs that are not reflected in the apparently low bill.
Of course, the product is still very young. It will be interesting to see how the development evolves!